For this RankSense webinar, we were joined by Danielle Rohe from UpBuild. She is the Senior Marketing Strategist at UpBuild, an end-to-end optimization agency dedicated to providing specialized digital marketing solutions. Danielle takes us on a journey of discovering Python, pursuing opportunities, and overcoming challenges to embrace SEO from a diverse background. Having professional experience of working with clients across every aspect of digital marketing, Danielle demonstrates an astute analysis of the Interesting Finds feature with Selenium.
Here is a full recording of the webinar:
https://youtu.be/-332dKUSI8k
During this webinar, Danielle aims to teach how to use Selenium to search mobile queries at scale and determine which SERPs are using the Interesting Finds feature.
Danielle Rohe Background and SEO Journey
Danielle started out with a Marketing background, having studied Public Relations in college. She then worked at radio sales and helped make coupon websites during the recession. There, she had to help incorporate Google Maps into those websites and help people locate their retailers. This was the first experience of computer programming she had. Danielle later joined an organization for women in computer science to learn more about coding. That is where she started to learn computer programming languages such as HTML, Java, PHP and CSS. Thus, she started working at a company which provided service to client websites. She later moved on to front-end development in that organization.
After some time, Danielle started working at Kroger with Angular and React. Danielle soon realized that she did not like programming with such advanced languages. So she started working as a Marketing Specialist at Signature Hardware for two years. She did that until she finally stumbled onto UpBuild and Python just over a year ago. While Danielle’s past experiences helped shape her desire to learn Python, she emphasized that it gave her a lot of creative freedom. Danielle found programming with Python very welcoming, as she found her calling in SEO. Her first attempt at Python was working on a script by Paul Shapiro that was for summarizing meta descriptions to scale on websites with complex site architecture. Embracing Python based SEO, Danielle got the best of both worlds: strategy and marketing.
Key takeaways
- Find your calling
- Danielle emphasizes that diversifying your experiences is a great way of finding and refining your passion.
- Your background doesn’t matter
- Meeting different people with various backgrounds in the SEO industry, Danielle highlights the strive to improve, rather than finding compatibility with your background
- What matters is getting started
- It is never too late to learn something new and reevaluate your perspectives. Danielle worked 5 different jobs in different industries, and she says that the most important aspect of achieving your goals is getting started.
What are “Interesting Finds” and Why Should You Care?
SERPS, also known as Search Engine Results Pages, are what you see when you search a query on Google’s search engine. They include organic search results, which are searches most relevant to the queries, paid advertisements, and other rich results like videos. As an SEO, your primary focus is to optimize websites for search engines and improve their visibility in the SERPs. Since Danielle works for an SEO company, the sudden and unannounced launch of Interesting Finds by Google was monumental.
This organic search feature is completely dynamic yet it could easily dictate the traffic flow to your website. This feature that Google added has been revolutionizing the mobile SERPs industry and completely changing it. If you do not have a mobile phone on you, you can access Google Chrome through your browser right now and go to Chrome Developer Tools using Ctrl-Shift-I on Windows or Ctrl-Option-I on Mac. Here, you can toggle a ‘device mode’ which lets you emulate any device while searching.
Clicking the blue button right next to Elements, will toggle the emulation on. After that, a simple search like “Best toys for kids 2021” will net you an Interesting Finds section.
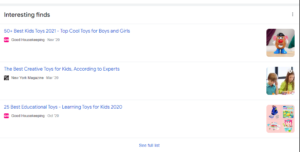
This feature has single-handedly changed the rankings and visibility of sites accessible through mobile devices. While publishers might celebrate how beneficial the feature has been in increasing their visibility, the same cannot be said for most e-commerce companies. Danielle first spotted this feature and its impact on the SEO industry when a client of hers suddenly received 4.7 clicks almost overnight from Interesting Finds, while the organic traffic simultaneously suffered a decrease of about 5 million.
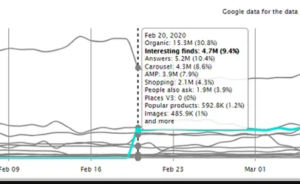
Danielle also emphasizes that this is not a well known feature. In an effort to investigate this further, she shows us how to use Selenium to search mobile queries at scale. This will also help determine which SERPs are using this feature, and where it frequently appears.
Walking through the Script
This script is automating the task of determining which SERPs are using the Interesting Finds feature at scale. Danielle starts with installing Selenium and the Chrome WebDriver. Selenium is a robust tool suite that allows us to create browser-based automation applications and tests. It is useful to scale scripts across different environments. Chrome WebDriver is an open source tool used to test web apps.
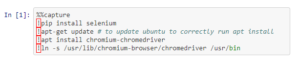
The first block starts with the %%capture command. In this Colab notebook, Danielle starts with this command, which lets the user capture all the outputs of each block that is run. Additionally, she runs all the commands with an ! exclamation mark in front of them. This allows the notebook to run the Python command as a shell command. For example, if you were to do this locally without using an online service like Jupyter or Colab, you would open the command prompt and download Selenium using pip install Selenium ( or conda selenium, based on what version of Python your local machine has). Here is an instance of me doing it:
However, this is not the case with Colab, as there is no terminal application to access. This is why Danielle runs the commands with a ! exclamation mark. Danielle then proceeds to update APT, and use it to install the WebDriver using the apt install chromium-chromedriver. APT is the Advanced Package Library, a useful and powerful tool to download the libraries you need, and is the Linux command to install most things. The -ln s command symbolically links (makes a shortcut to) the first path to the second path.
Setting up I/O, Selenium and ChromeDriver
Since Colab notebooks areis a shared research tool, you can mount your Google Drive in order to upload your queries.csv. This file should contain a list of all the your queries that you want to run this script on. The only parameter is that each query should be one row, since the automated script takes each line of the .csv file as an argument.

Once the Google Drive is mounted, you can select the folder icon in the left menu of the notebook and then open the “gdrive” folder. Expand “My Drive” and then “Colab Notebooks” to ensure that your queries.csv file is saved at the path of ‘/content/gdrive/My Drive/Colab Notebooks/Interesting Finds/queries.csv’. If not, right click to copy the path and replace it in the “with open” line below. After successfully mounting the drive, Danielle then proceeds to import the libraries needed.
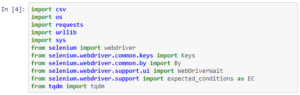
Using the import command, she imports various useful libraries and selenium elements. The next step is to make sure we can automate the emulation like we did earlier using Chrome Developer Tools. We do this using ChromeDriver.
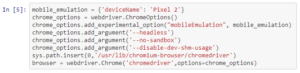
Danielle starts off by defining a dictionary with the field of deviceName, which translates to what device to emulate. She goes with Pixel 2, as that is the phone she uses normally. After this, she creates an instance of ChromeOptions() by defining chrome_options. This is useful as you can pass this object later into the ChromeDriver constructor. That which has convenient methods for the emulation. She then runs the browser automation as the webdriver.Chrome([arguments]) instance.

Danielle then proceeds to make a new directory on Google Drive titled Interesting Finds for all the outputs such as the .csv files. These outputs indicate which queries included the features and what links were in the feature when present.

Now that we have the folder ready for the output, we can proceed to read the data from the .csv file. Danielle uses the open function to get the queries.csv file from earlier and create a list of queries from it.

This is where Danielle actually uses Selenium. Since we are emulating the browser, we can set the browser window size to a custom fit. If you change the size, which is preset to 640*360, you will have to reflect the changes in the following code block.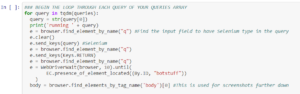
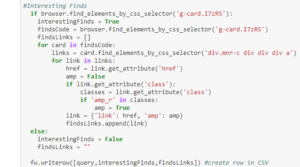
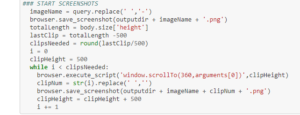
This is the main function, which builds upon the previous functions and executes the primary purpose of the project. It loops through the queries and inspects the elements page of the SERPs to find all the elements that are interesting. The screenshots function keeps taking screenshots in a loop until it has met the amount of clips needed.
While this looks daunting at first, Hamlet assures that everyone approaches complexity differently. He explains that when he writes code, he thinks of different things that his project has to do, and then slowly assembles it together. Danielle agrees, and explains how she started with just basic thoughts and building upon it by asking questions such as: What do I want to do with the SERP?, How do I want to print the queries, etc. It was a learning curve and different online resources helped her.
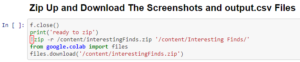
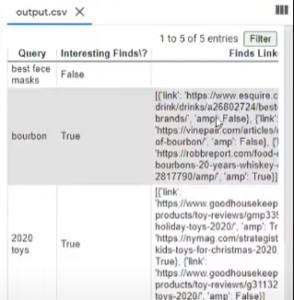
Finally, Danielle exports the output and it zips all the screenshots into a folder while the code also writes to the csv file that we created at the start.
Closing Remarks
Once again, we would like to thank Danielle Rohe for the informative presentation of utilizing the Selenium library. If you would like to contact her, you can do so on Twitter. Danielle’s script and subsequent hosting instructions are on GitHub for anyone to leave questions or suggestions. Be sure to visit @RankSense on Twitter for new updates on upcoming events.