By submitting your email address, you agree to receive follow up emails about RankSense’s products and services. You can opt out at any time by clicking the link in the footer of our emails. We share your information with our customer relationship management partners. For information about our privacy practices, please see our privacy policy
Getting Started with NLP and Python for SEO [Webinar]
by Michael Van Den Reym | July 21, 2022 | 0 Comments
Custom Python scripts are much more customizable than Excel spreadsheets.
This is good news for SEOs — this can lead to optimization opportunities and low-hanging fruit.
One way you can use Python to uncover these opportunities is by pairing it with natural language processing. This way, you can match how your audience searches with your actual page titles.
In this webinar, originally presented by Michael Van Den Reym with Maura Loew, Ph.D. from RankSense, you’ll learn how to use Python and NLP to:
Count the number of words in search queries and title tags
Check mismatches between the words in your user’s search queries and your meta title tags.
Gain insights to make more appealing title tags and/or spot content gaps
This allows you to find easy mismatches and quick wins between user search queries and actual page title tags.
In short, this workflow will let you better align your page title to what users are actually searching for.
Michael Van Den Reym formerly worked for Intracto. He is now a Data Science Expert at iO Digital.
Here’s what you’ll need for this workflow:
Google Colab
Python modules: pandas, files, io, nltk, re, stop_words, levenshtein
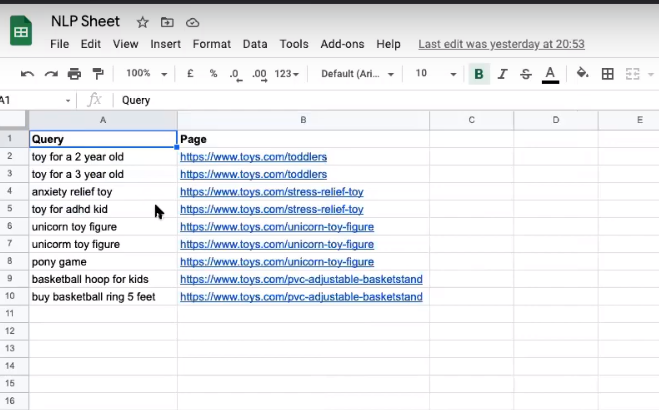
A sheet/csv file with a list of queries by page
A sheet/csv file with meta titles
For the latter two items on this list, refer to your SEO platform or tech stack. Or, you can use the Search Analytics for Sheets or Supermetrics add-on in Google Sheets.
Maura Loew, Ph.D.: Can you give a basic overview of what natural language processing is?
Michael Van Den Reym: Natural language processing, or NLP, involves analyzing natural language with the help of algorithms and computers.
Some NLP tasks are more basic in nature — things like counting words, translating words, or catching typos. On the more advanced level, NLP can be used for content creation.
Editor’s Note:seoClarity’s Content Fusion is an example of this more advanced NLP. It runs on an NLP model that lets our clients create authoritative content at scale.
How Python and NLP Work Together
ML: Can you give an overview of what your script is doing and how it uses NLP?
MR: My script compares the terms that the Google visitor uses to the meta titles of your web pages. It counts the common words and it also makes the distinction between singular and plural, so if it’s the same word it will still account for these differences.
ML: So we’re looking at the list of queries that come into a page, the meta titles on the page, and then we’re using NLP to compare them, to see if there’s anything missing in the meta titles. And the reason we’re using NLP is because we’re not looking for just an exact match — the exact query in the title — but we want to give it some flexibility, like if it’s plural versus singular.
Step 1: Import the Modules [12:39]
MR: After you have two sheets (one with the URLs of your website along with their title tag, and the other with Search Console data of queries next to the page they relate to) we’re going to compare the queries and the meta titles.
(Prepare two sheets before we move into importing modules.)
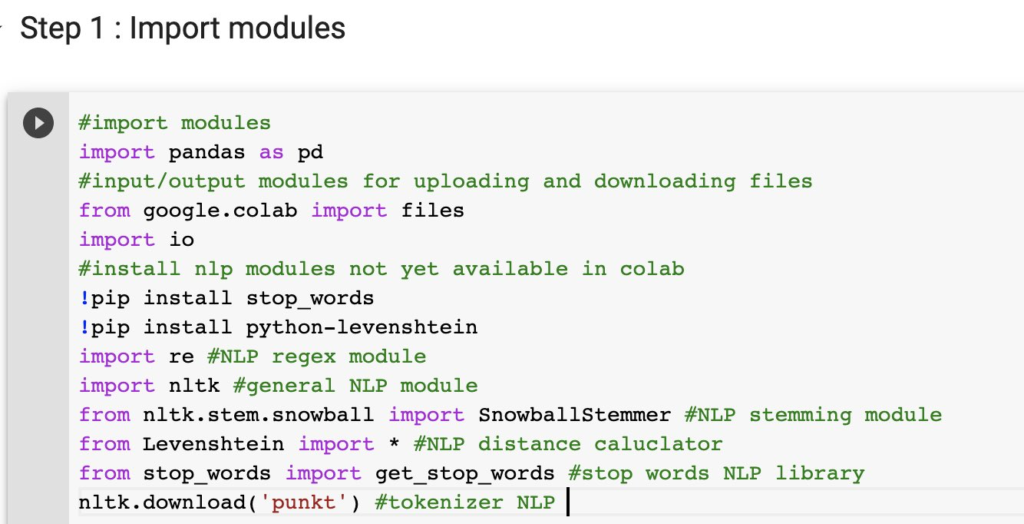
Note: The NLP modules stop_words and levenshtein are not standard, so you have to install these first. You will also use pandas, files, io, re and nltk modules.
MR: Then we will load all the modules. I use the “panda” module in almost every script. It’s for displaying data and analyzing data.
The next two modules are for uploading new CSV files from the sheet.
(Adding modules to the script.)
I also use two modules that are not yet available in the default CoLab environment. One module is “stop_words,” and this will contain all stop words like “and,” “in,” “or,” etc. The very tiny words without any meaning — we want to exclude them from the analysis.
ML: So later on, when we look back at our query list, we don’t want to consider “toys for a two year old” to be different from “toys two year old.”
MR: Yes, correct. I also have the “python-levenshtein” module, which is a good module to filter out typos. And with this Levenshtein distance, it’s the added distance of a string, like between cat and dog you have a Levenshtein distance of three.
ML: So by looking at the distance between words, meaning how many letters are different, we can tell if there’s two words that are variations of the same word, like a typo.
MR: Exactly. I also used the “Regex” module and the “NLTK” module, which is the default module for the NLP programs. That will be used for splitting the queries and the meta titles into different words.
The “SnowballStemmer” is a mobile NLP library and this will stem a word. So, if you want to make a plural word a singular word, or if there is a verb it’ll take the stem of the verb.
ML: So this way we are just considering singular and the verb stem, so that we are ultimately not going to consider it different if the verb tense is different.
MR: Then we also have to download two NLTK library files.
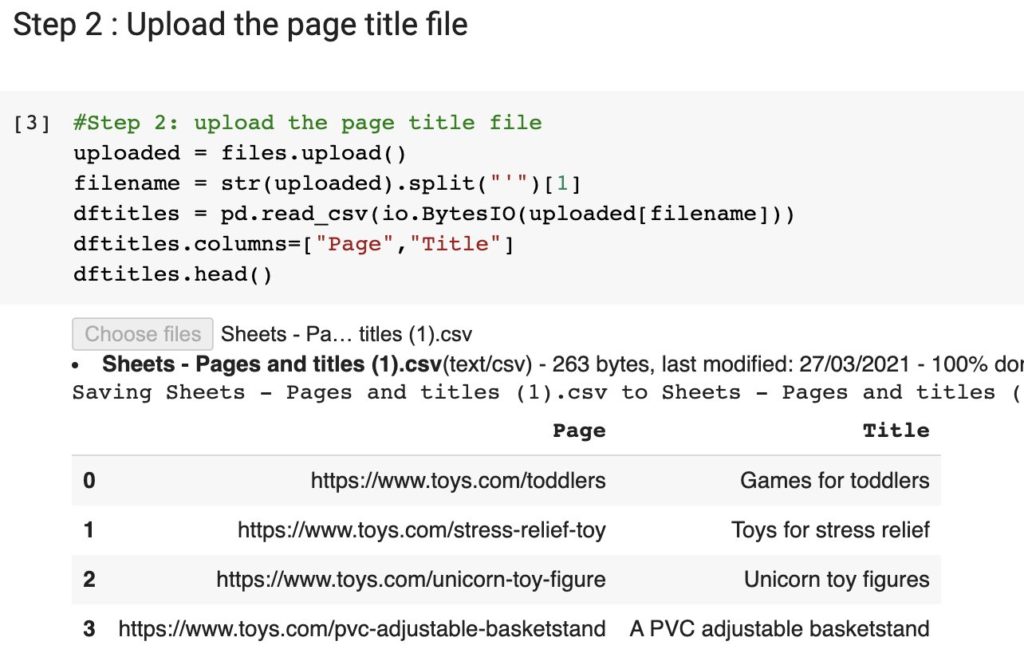
Step 2: Upload the Page Title File [18:09]
MR: Now we’ve installed the modules and we’re going to upload our CSV file. We’ll get started with the page titles.
ML: This is where we start getting into this Excel version for Python. Now it’s been loaded into a data frame.
MR: And if you see in this script, I split this string — the part between the second quote and the third quote.
The way that the uploaded file here is used by Google CoLabs, they display all of the file but we only need the title.
Immediately convert this CSV file to a dataframe “dftitles.head.”
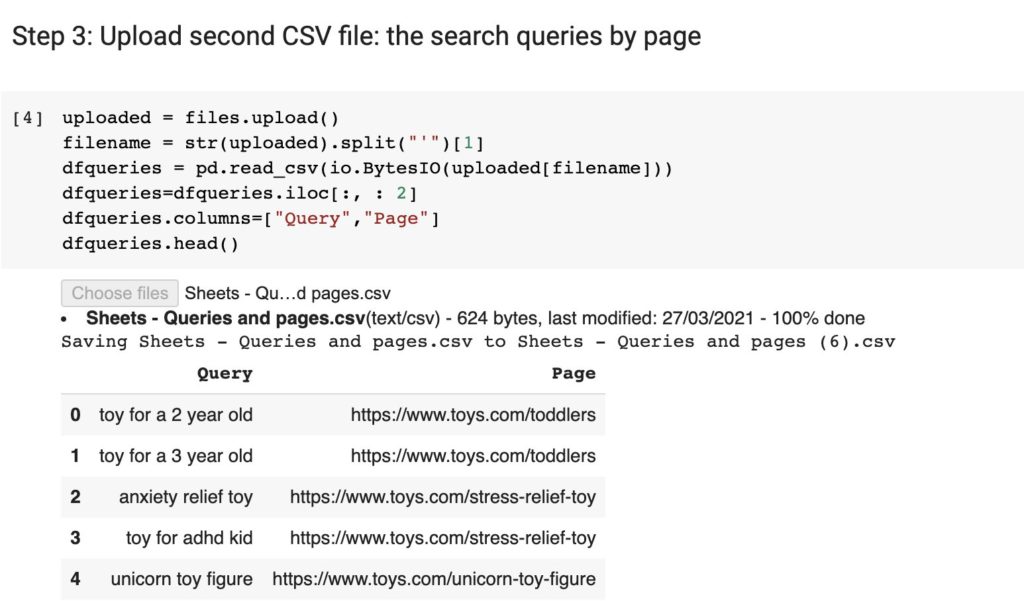
Step 3: Upload the Search Queries by Page [20:30]
MR: We’re going to do the same for the other CSV file — the one with the queries.
We have now an appended dataframe with the queries and the page. So, for every top query you can find a page to go along with it.
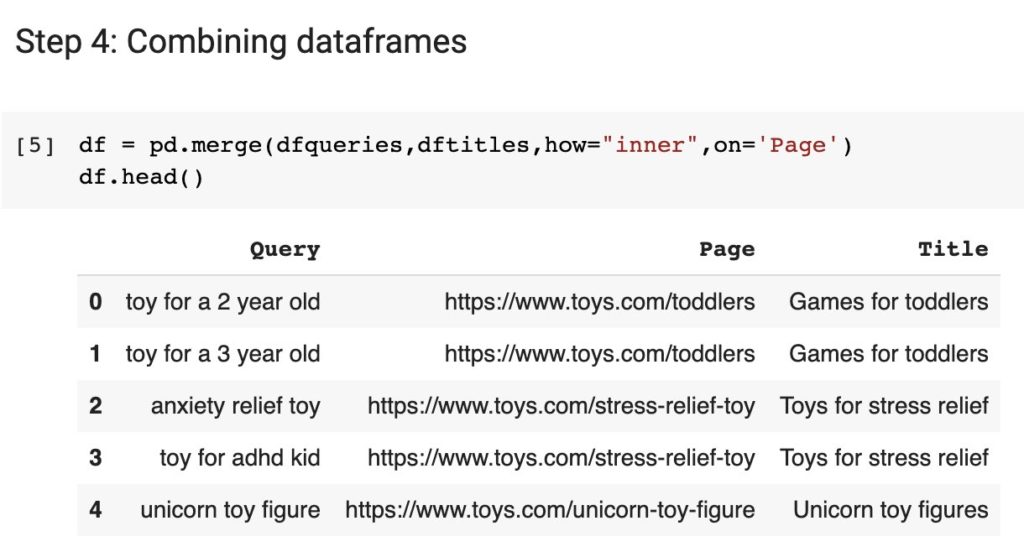
Step 4: Combine the Dataframes [21:07]
MR: Now we are going to combine these files, and you’ll see that both files have a column called “Page” so we will merge them on the page column.
ML: So instead of having two separate dataframes, now we just have one that has all of the information we need.
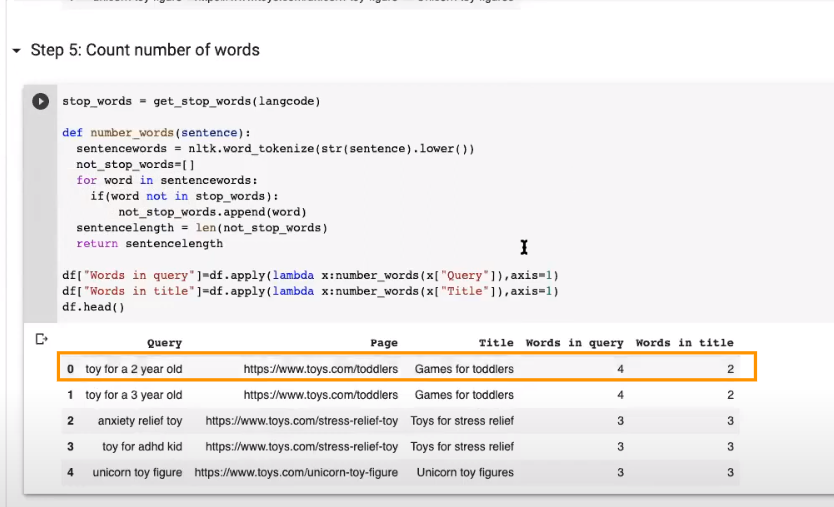
Step 5: Count the Words in Queries and Titles [21:40]
MR: I’m going to count the number of words, but I won’t include the stop words. You can make a list of stop words by language, so the language code would be EN for English. Then I run a function that first will split the sentence into different words with the NLTK function “word_tokenize.”
Then I make a list with all the words that are not stop words by looping over these words in the “word_tokenize.” I include them in the list not_stop_works, and then I count the number of words with “len.”
ML: And we’re going to do this for both the query and the title?
MR: Yeah. We are going to do it for both the query and the title. We are going to make a new column. In this column there will be the number of the words in the query and the number of words in the title.
ML: So this is telling us how many words are in each, not counting any small stop words like “of” or “and.”
MR: Indeed. So I will run the query so you can see.
MR: For example, here we have the query “toy for a 2 year old” and it’ll count it as four words in the query because the “for” and the “a” will not be counted.
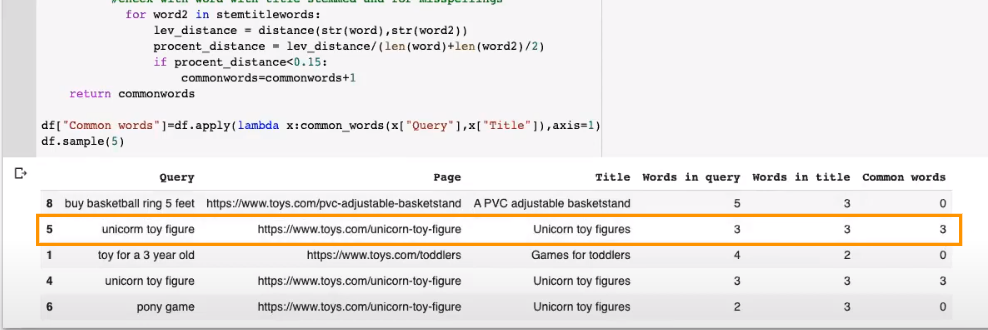
Step 6: Count the number of common keywords [24:11]
Note: For a better comparison we will remove special characters and focus on the stem of the words (singular, plural, conjugations, etc)
MR: In the next step, we count the number of common words between the query and the page title. I’ll use the “SnowballStemmer” module that will take the stem of the word. I also will make a list of words in the title and then stem the list of words in the title.
We will make a list with all the stem words in that title, and we will do the same for the query.
ML: And so what we’re doing here is making sure that we remove any plurals or any verb conjugations, and we just have the stem of the word.
And this is why it’s called natural language processing. We’re taking words, which usually a script like Python wouldn’t understand, but with natural language processing, it’s able to find the stem of a verb, or what is the singular version of a noun.
MR: That’s also why it’s much more efficient than using a spreadsheet because you can’t have all these rules within a sheet.
Also what I do here is make a title of the page without any spaces or special characters. So with a RegEx that will only keep the words and not the special characters.
ML: So we’ve taken the title of the page and we are replacing all of the spaces and only having the words all next to each other.
MR: Then there are two variables: the levenshtein distance and the number of common words.
Then I will look through all the words within the query, the stemmed words. First I check if it’s a stop word. Then I will see if the word is present in the title.
If the word is present there, then you know it’s a common word between the query and the page title. If the word is not literally found, then I will use another approach.
You can see that I also use the stemmed version of the title words, and then I calculate the levenshtein distance between the stem of the title word and the stem of the query word.
The levenshtein distance is the difference in the number of characters between two words.
Then I can find if they differ a lot or not, and if they are very close to each other, like a distance of less than 15%, I will count it as a common word.
ML: It’s not that we’re catching plurals or verb conjugations anymore because we already took care of those. So this would mostly be used for typos.
MR: If I run this cell, you see in the second row over here, there was a typo in the word “unicorn” with an M instead of an N but it will count it as a common word, so you have three common words for this example.
ML: And we also have the plural counted as the same word between “toy figure” and “toy figures.”
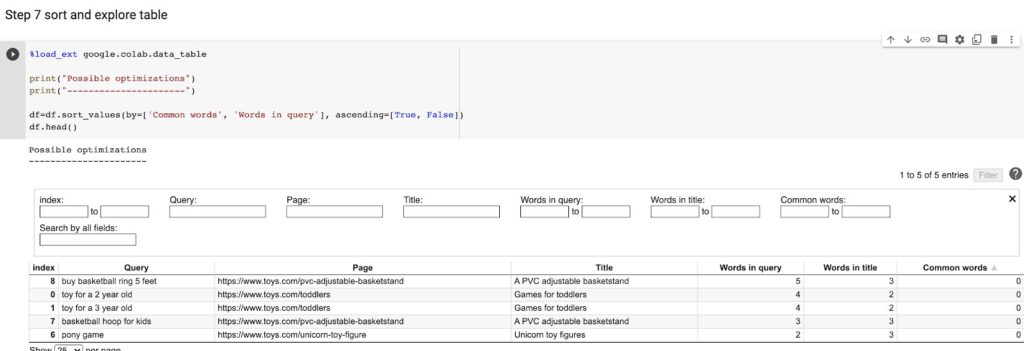
Step 7: Sort and Explore the Table [29:58]
MR: Now I’ll use a useful Google CoLabs extension. The dataframe will be sorted by the number of common words, and then you can immediately spot some improvements.
Here, for example, the query “buy basketball ring 5 feet” differs a lot from your page title, so you may want to update it.
ML: And you can spot gaps too, where maybe you need a different kind of page.
Step 8: Export and Download [31:46]
MR: These are the scripts. I also have a CSV export of it, in case you have to share it with a client. Or, if you want to share it with your content team, they can work further on it.
ML: And also, if you wanted to just work in this table, there’s a filter button where you can filter the queries or the pages. Let’s say all of your product URLs have /P in them, for example, then you could filter and search for those.
MR: You also can combine the filters in a much easier way than in a spreadsheet.
Optimizing Page Title Tags at Scale
Once you’ve discovered how your audience searches so you can align your on-page SEO with audience demand, it’s time to implement the pages.
Unfortunately, doing this manually just isn’t a feasible solution — especially when you’ve discovered hundreds or thousands of potential optimizations.
That’s where SEO technology comes in. With SEO execution platform ClarityAutomate, you can update and optimize your page title tags across your site with a few clicks.
Bonus: Advanced Version [33:35]
MR: I also made another notebook but instead of starting from the spreadsheet, it gets the data automatically.
ML: We’re not going to upload two files — we’re just going to grab the data. This is a great one to learn also for anyone who’s learning Python for SEO because being able to just get Search Console data directly into your Google CoLab is super useful.
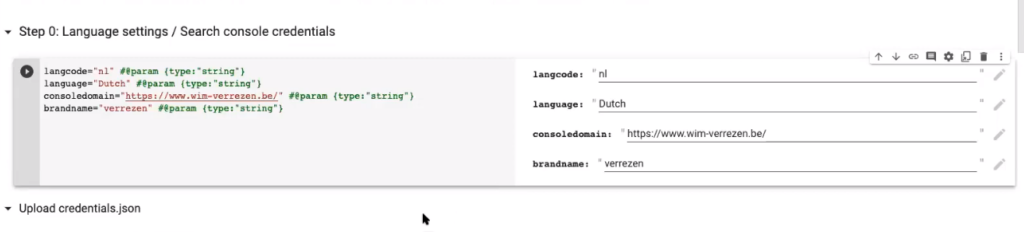
MR: So you see that here I added two additional fields: one for the Google Search Console domain, and another one for the name of the brand so we can filter out the branded queries.
And then of course, because you have to connect with the Search Console API, we also need to upload your credentials file.
ML: Where would you get this from?
MR: The Google developer console. You can get it for free actually. You can enable the Search Console API and a key.
ML: This key gives full access to your Search Console account, so you don’t share it with anybody unless they already have access to your Search Console account.
MR: In the script, I also install the Google Search Console, the BeautifulSoup, and Requests modules. The latter two modules are used for scraping the meta title of the page, so you don’t need to have the CSV file with titles anymore.
ML: So BeautifulSoup works like a crawl or a scraper tool, where you would use a crawler to get the titles. Instead, we’re just going to use BeautifulSoup to go visit those pages, grab the titles, and retrieve them.
MR: Right, the Python equivalent of a crawler. Here, you will see, I will authenticate Google Search Console using my credential file.
Select the right account with the domain of the variable I used. Then I select the date from today for the previous 30 days. Then I get the queries and the pages.
Then I look through the report and add all the keywords and the pages, plus the lift in impressions, CTR, and position within a keyword list. Then I will convert it to a dataframe.
Editor’s Note: seoClarity offers a built-in and fully customizable crawler that lets you set your own crawl depth, optimize the crawl speed, and more.
ML: So we’re just feeding information into our little Excel within Python.
MR: Yes, indeed. And then I rename the columns to make it easier. So, we set an index and I will limit the amount of queries to 100 for the example.
ML: That was one thing I was wondering about, because sometimes when I have tried to use the Search Console API within CoLab, it just times out, because there’s too much data.
MR: This function will scrape the meta title of a certain URL, and it will use the requests module to scrape the URL and the BeautifulSoup module to interpret the HTML. Then I find the meta title of the web page and return it.
If we make a new column, “Title,” in the dataframe and use this function for every landing page, then we get a new dataframe. This of course takes a bit more time because it has to strip all the URLs dataframe.
ML: This is similar to when you start a website crawl and it takes a while to go through all of those pages, but in a crawler you see the progress. Here, we just see a spinning circle. So we just have to remember to be patient.
MR: From now on the goal is exactly the same as the previous notebook or script, so you can already execute it. This one is completely the same.
Here we are going to use the data table so we spot some improvements. For example, here the title is about maintaining a garden, but we see lots of queries with “lava stone” and that tells us that we will need to write a blog about how lava stones can help you in maintaining a garden.
ML: So this is an example with a real-life site where we’re finding situations where people are searching for something, but our content doesn’t exactly match it. So it gives us an idea of new content to create.
MR: Then you can recommend to clients that they should make a new article or improve their existing content.
Editor’s Note: RankSense was acquired by enterprise SEO platform seoClarity in 2022. This acquisition furthers the growth of seoClarity’s new SEO execution platform, ClarityAutomate.
Custom Python scripts are much more customizable than Excel spreadsheets. This is good news for SEOs — this can lead to optimization opportunities and low-hanging fruit. One way you can use Python to uncover these opportunities is by pairing it with natural language processing. This way, you can match how your audience searches with your...
As we continue to improve the RankSense app for Cloudflare, we are always working to make the app more intuitive and easy to use. I'm pleased to share that we have made significant changes to our SEO rules interface in the settings tab of our app. It is now easier to publish multiple rules sheets and to see which changes have not yet been published to production.
For the following Ranksense Webinar, we were joined by Antoine Eripret, who works at Liligo as an SEO lead. Liligo.com is a travel search engine which instantly searches all available flight, bus and train prices on an exhaustive number of travel sites such as online travel agencies, major and low-cost airlines and tour-operators. In this...