I recently read Aleyda’s excellent post about using Chrome Developer Tools for SEO, and as I’m also a big fan of DevTools, I am going to share my own use cases.
Misplaced SEO tags
If you are reviewing correct SEO tag implementations by only using View Source, or running an SEO spider, you might be overlooking an important and interesting issue.
I call this issue misplaced DOM tags, and here is one example http://www.homedepot.com/p/Kidde-Intelligent-Battery-Operated-Combination-Smoke-and-CO-Alarm-Voice-Warning-3-Pack-per-Case-KN-COSM-XTR-BA/202480909
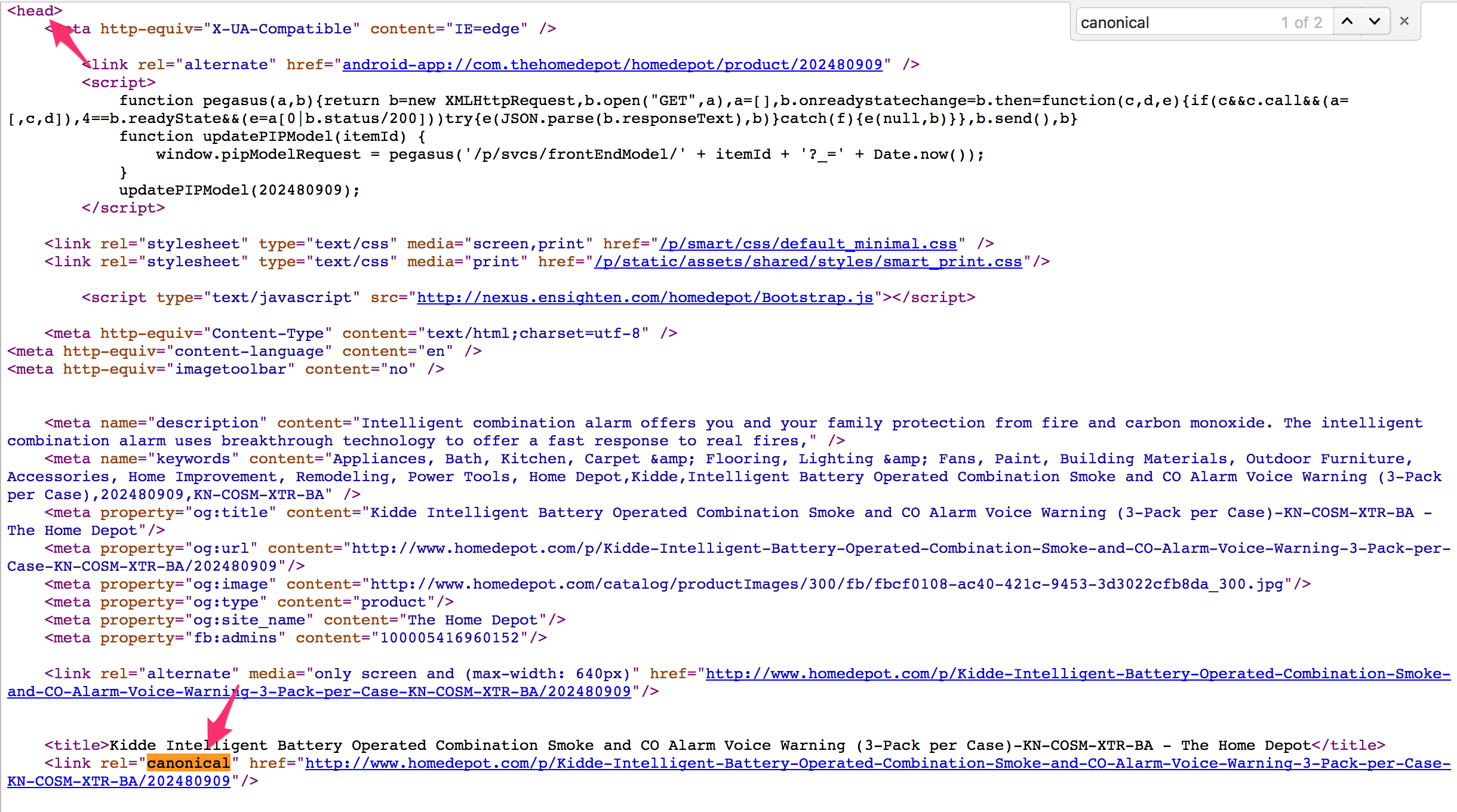
If you check this page using View Source in Chrome or any other browser, you would see the canonical tag correctly placed inside the <HEAD> HTML element.
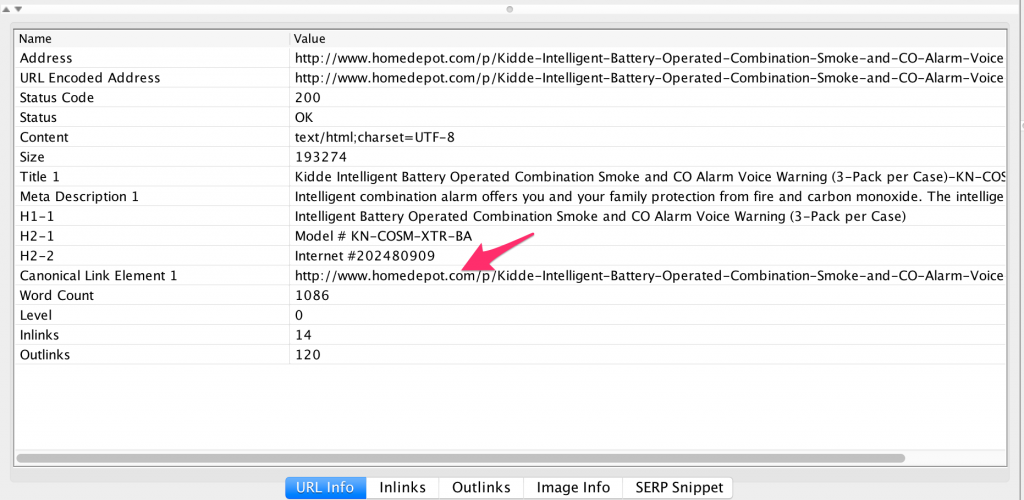
Similarly, if you check this page using your favorite SEO spider, you’d arrive at the same conclusion. The canonical tag is inside the <HEAD> HTML element, where it should be.
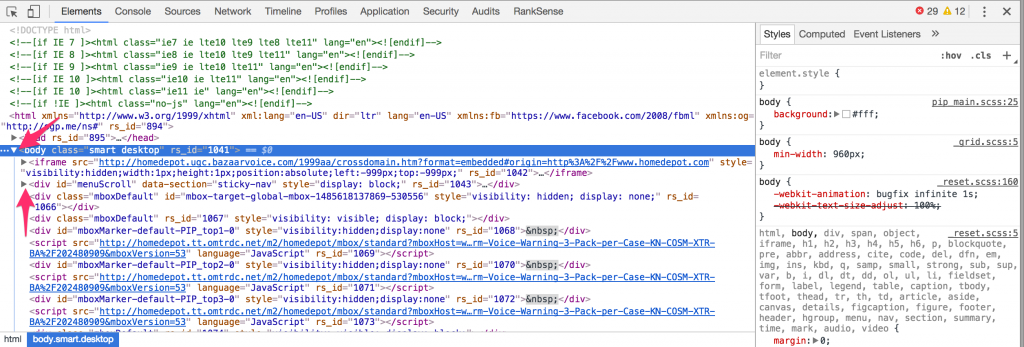
Now, let’s check again using the Chrome Developer Tools Elements tab.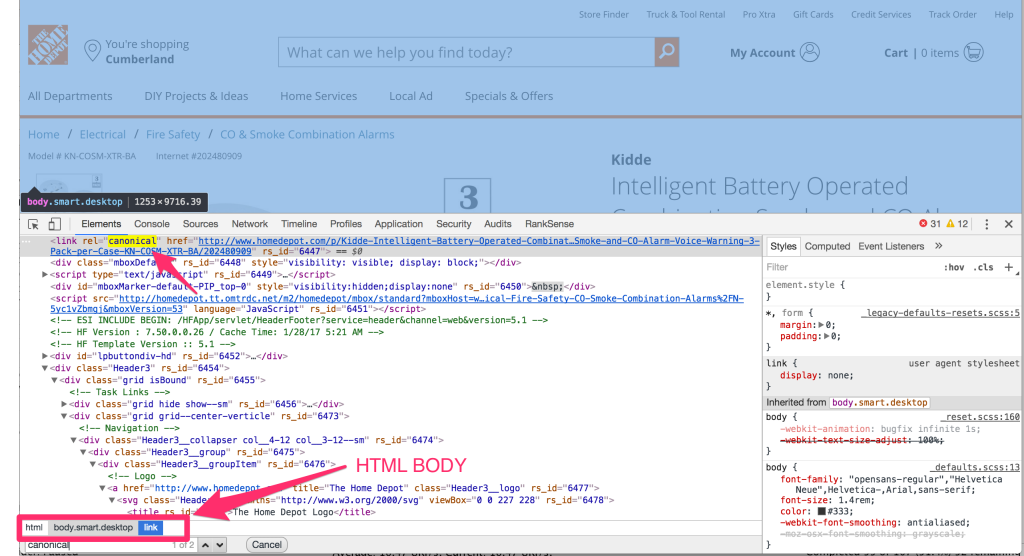
Wait! What?? Surprisingly, the canonical tag appears inside the <BODY> HTML element. This is incorrect, and if this is what Googlebot sees, the canonical tag on this page is effectively useless. Then we go blaming the poor tag saying that it doesn’t work.
Is this a bug in Google Chrome Developer Tools? Let’s review the same page with Firefox and Safari Developer Tools.
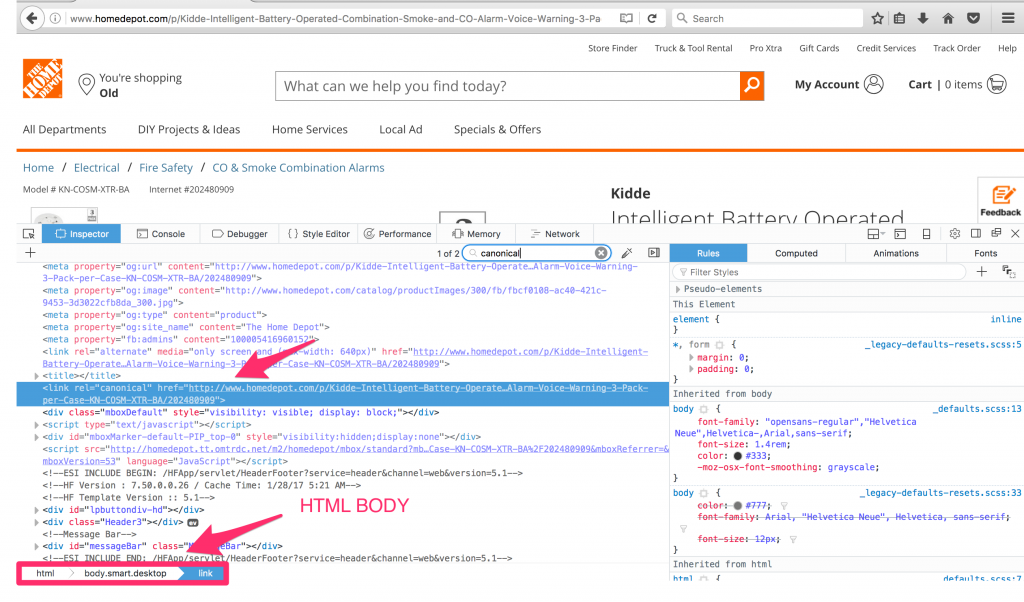
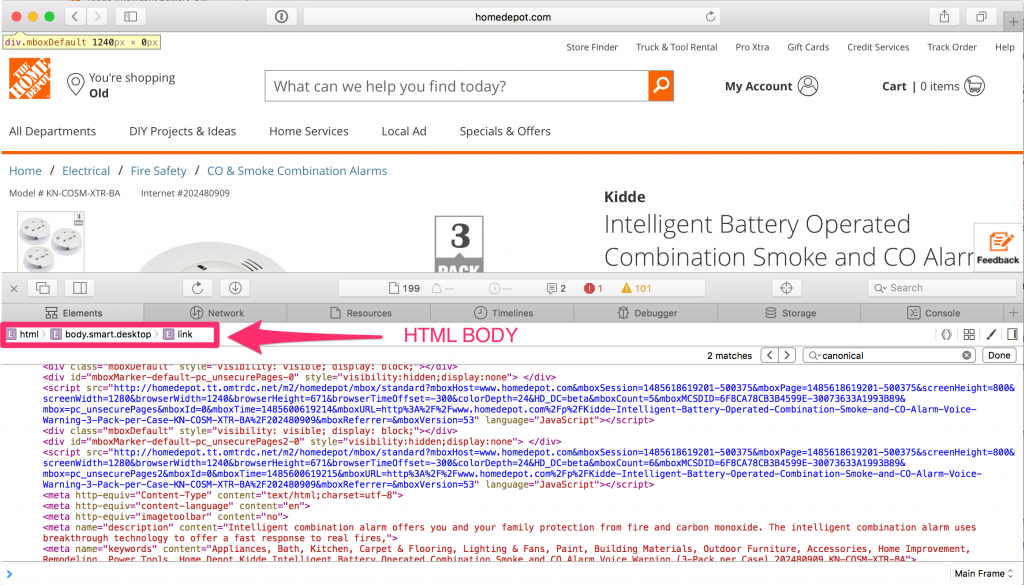
You can see the same issue is visible in Firefox and Safari too, so we can safely conclude that it is not a problem with Developer Tools. It is very unlikely all of them would have the same bug. So why is this happening? Does The Home Depot need to fix this?
Let’s first look at how to fix this to understand why it happens.
We are going to save a local copy of this page using the popular command line tool curl. I will explain why it is better to use this tool than to save directly from Chrome.

Once we download the web page, open it in any of the browsers to confirm the problem is still visible in the DevTools. In my case, I didn’t see the issue in Chrome, but saw it in Safari. I’ll revisit why the discrepancy when we discuss why this happens.
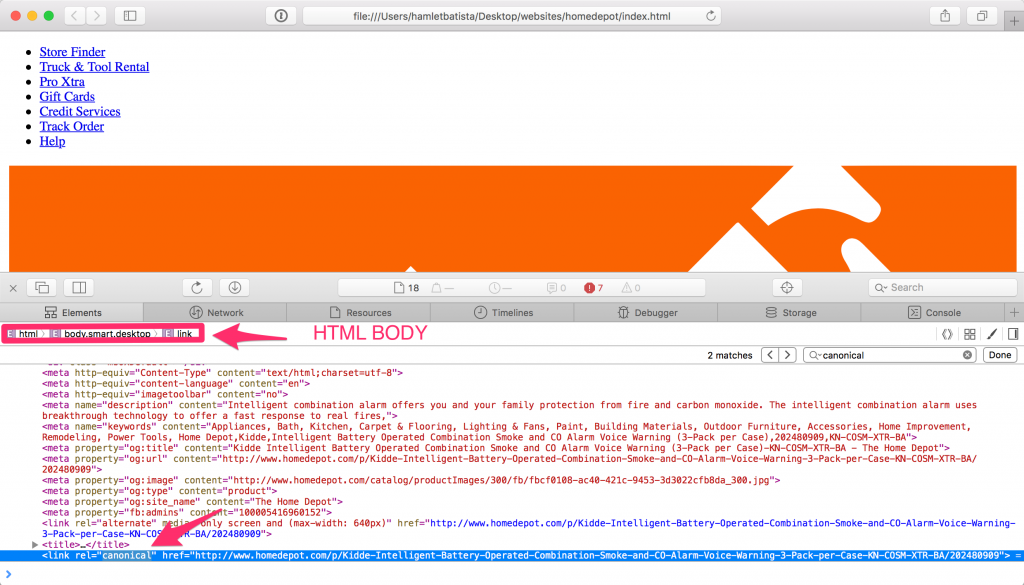
Next, in order to correct the issue we will move the SEO meta tags so they are the first tags right after the opening <HEAD> HTML tag.
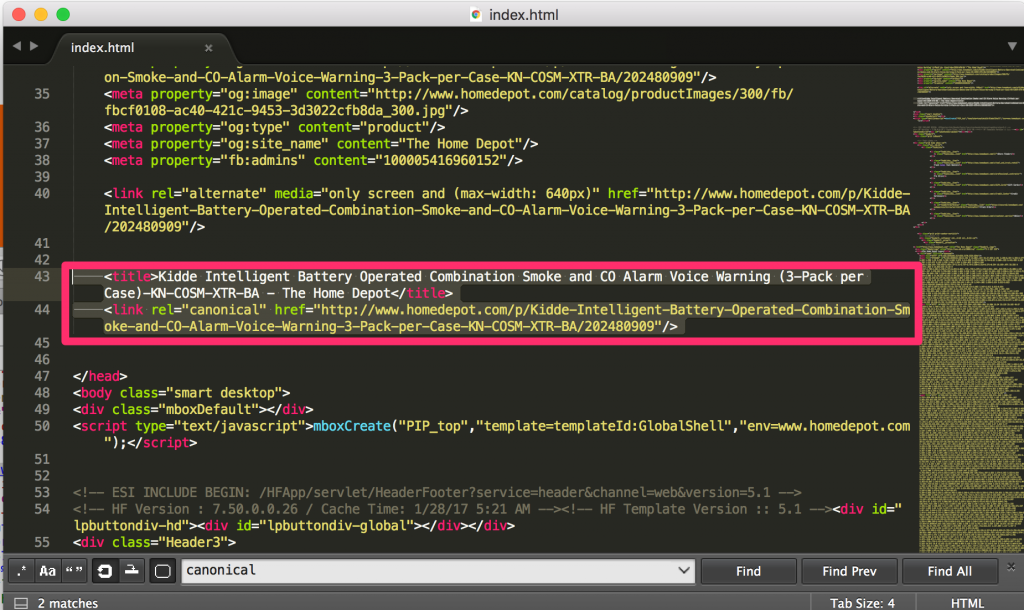
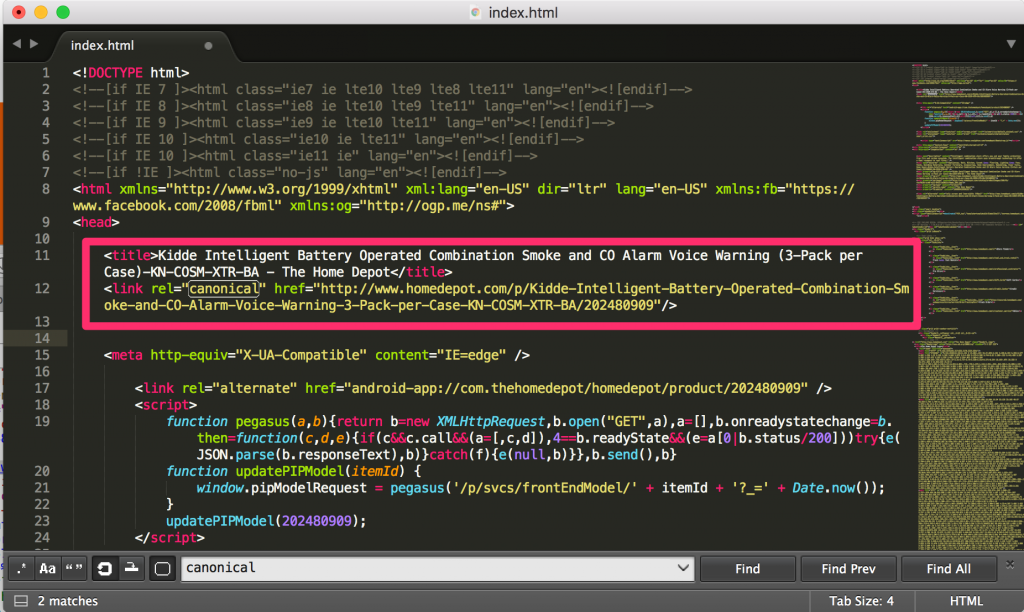
Now, let’s reload the page in Safari to see if the canonical still shows up inside the <BODY> HTML tag.
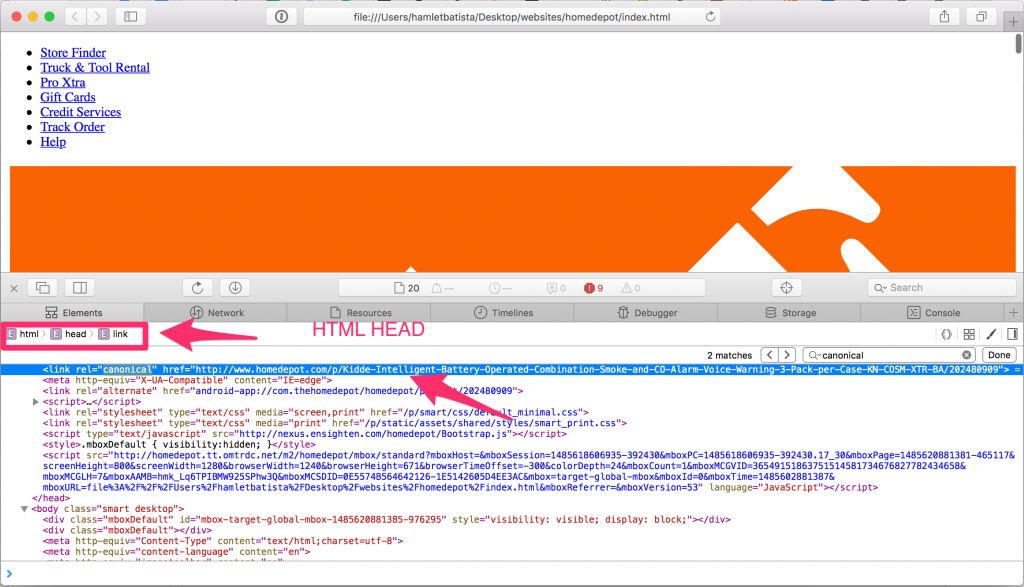
Bingo! We have the canonical correctly placed, and visible inside the HTML <HEAD>.
In order to understand why this addresses the issue, we need to understand a key difference between checking pages with View Source, and inside the Elements tab in the web browsers’ DevTools.
The Elements feature has a handy feature that allows you to expand and collapse parent and child elements in the DOM tree of the page. In order for this feature to work, the web browser needs to parse the page and build the tree that will represent the DOM. A common issue with HTML is that it often contains markup errors or invalid tags placed in the wrong places.
For example, if we check the page using https://validator.w3.org/nu/?doc=http%3A%2F%2Fwww.homedepot.com%2Fp%2FKidde-Intelligent-Battery-Operated-Combination-Smoke-and-CO-Alarm-Voice-Warning-3-Pack-per-Case-KN-COSM-XTR-BA%2F202480909
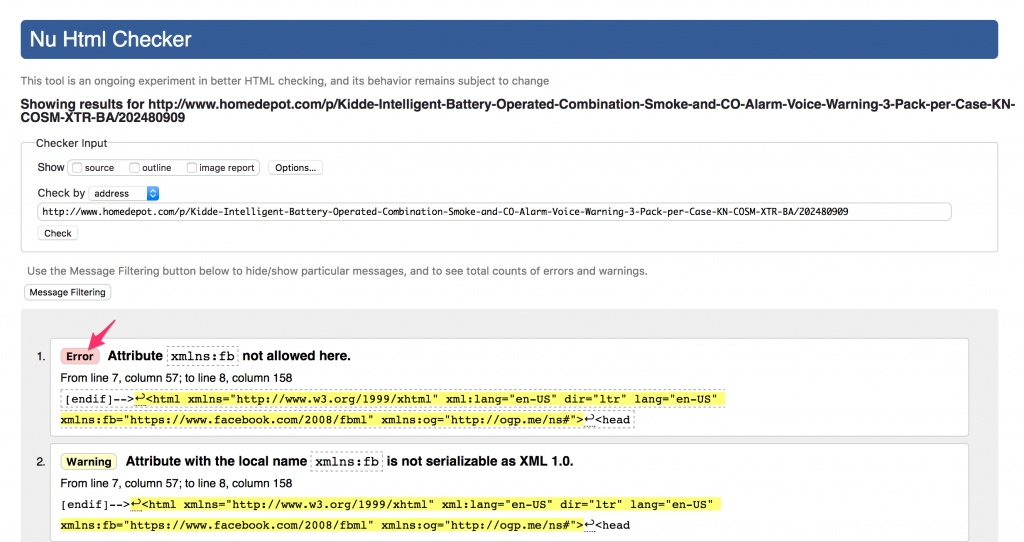
You can see this page “only” has 61 HTML coding errors and warnings.
Fortunately, web browsers expect errors and automatically compensate for them using a process called HTML linting or tidying. A popular tool that does this is https://infohound.net/tidy/ by Dave Raggett at W3C.
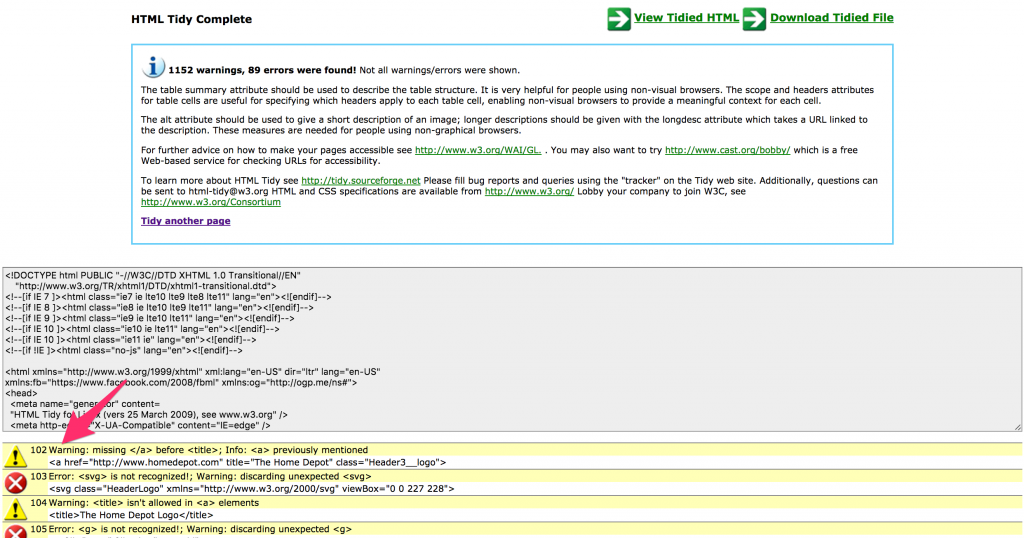
The tidying process works by adding missing closing tags, reordering tags, etc. This works flawlessly most of the time, but it can often fail and tags end up in the wrong places. This is precisely what is happening here.
Understanding this allowed me to come up with the lazy trick to move the SEO tags to the beginning of the head, because this essentially bypasses any problems introduced by other tags. 🙂
A more “professional” solution is to at least fix all the errors reported between the HTML <HEAD> tags.
Can we tell if this is affecting Googlebot or not?
It is fair to assume that as Google is now able to execute JavaScript, that Google’s indexing systems need to build DOM trees just like the main browsers do. So, I’d not ignore or overlook this issue.
A simple litmus test to see if the misplaced canonicals are being ignored is to check whether the target page is reporting duplicate titles and/or duplicate meta descriptions in Google Search Console, or not. If it is reporting duplicates, correct the issue as I explained here, use Fetch as Googlebot, and re-submit the page to the index. Then wait and see if the duplicates clear.
Following redirect chains
Another useful use case is reviewing automatic redirects from desktop to mobile optimized websites, or from http to https or viceversa directly in your browser.
In order to complete the next steps, you need to customize DevTools a little bit.
- Tick the checkbox that says “Preserve Log” in the Network tab so the log entries don’t get cleared up by the redirects
- Right-click on the headers of the Network tab, and select these additional headers: Scheme, Vary, and optionally Protocol to see if the resources are using the newer HTTP/2 protocol
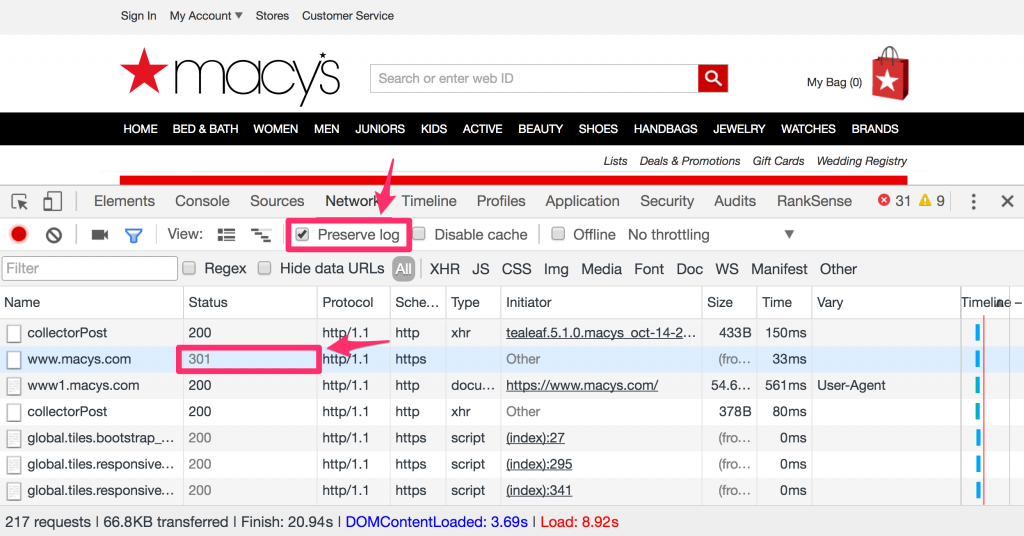
In this example, we opened https://www.macys.com, and you can see we are 301 redirected to http://www1.macys.com, from secure to non-secure, and we can also see that the page provides a Vary header with the value User-Agent. Google recommends the use of this header with this value to tell Googlebot to try refetching the page but with a mobile user agent. We are going to do just that, but within Chrome using the mobile emulation feature.
Before we do that, it is a good idea to clear the site cookies because some sites set “desktop sticky” cookies that prevent the mobile emulation from working after you have opened the site as a desktop user.
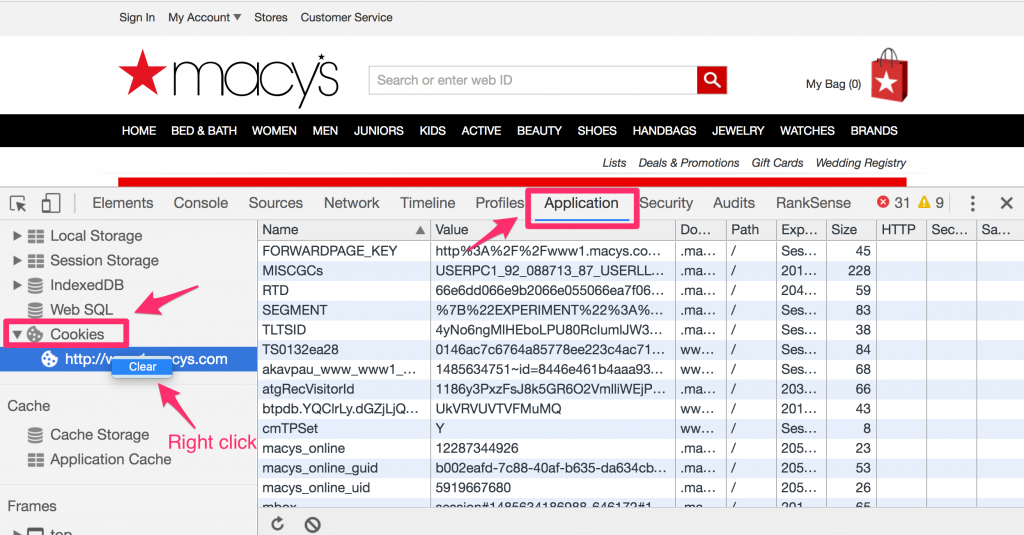
Let’s clear the network activity log and get ready to refresh as a mobile user. Remember that we will open the desktop URL to see the redirection.
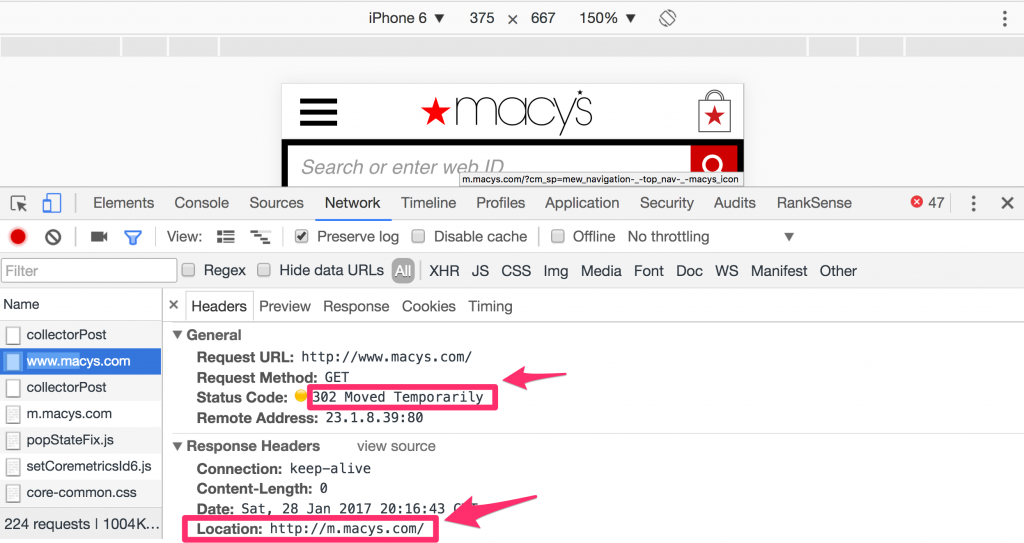
In this case you can see that Macys correctly 302 redirects to the mobile site at http://m.macys.com, which is consistent with Google’s recommendation.
Sneaky affiliate backlinks
As Aleyda mentioned in her post, we can use DevTools to find hidden text, and some really sneaky spam. Let me share with you a super clever link building trick I discovered a while ago while auditing the links of a client’s competitor. I used our free Chrome DevTools extension as it eliminates most of the manual checks. You can get it from here.
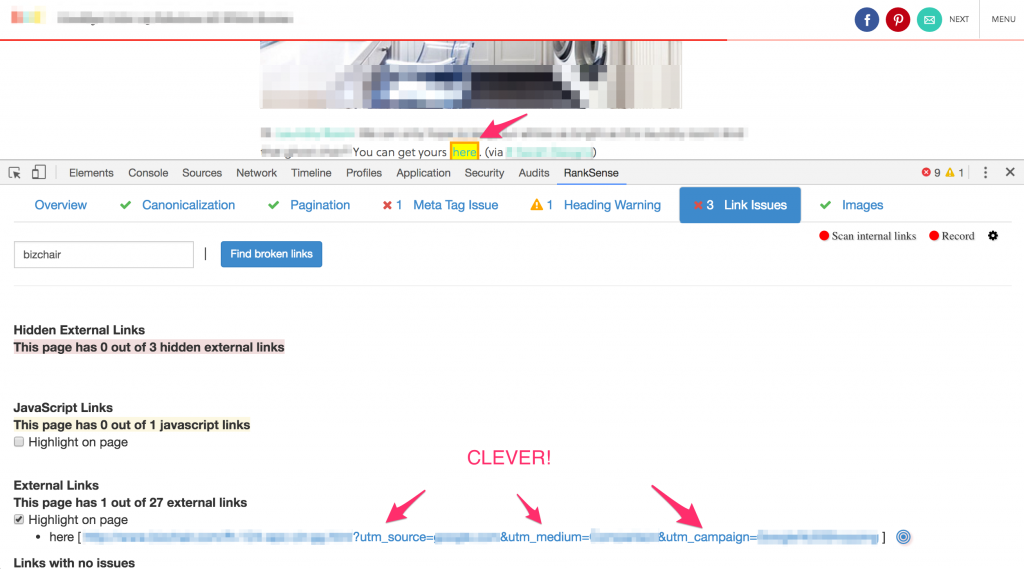
To most of you, and to most Googlers, this looks like a regular backlink and it doesn’t raise any red flags. The anchor text is “here”, and it is directly in the editorial content like most editorial links. However, coming from an affiliate marketing background, I see the extra tracking parameters can be effectively used to track any sales that come from that link.
I’m not saying they are doing this, but it is relatively easy to convince many unsophisticated bloggers to write about your product, and place affiliate links like this back to your site to get compensated for sales they generated. Sales you would track directly in Google Analytics, and maybe even provide reporting by pulling stats via the GA API.
Now, the clever part is this one: they are likely setting up these tracking parameters in Google Search Console so Googlebot ignores them completely, and it is normal to expect utm_ parameters to be ignored. This trick effectively turns these affiliate links into SEO endorsement links. This is one of the stealthiest affiliate + SEO backlink tricks I’ve seen in many years reviewing backlink profiles!
Troubleshooting page speed issues
Let’s switch gears a bit, and discuss pagespeed from an implementation review perspective.
Let’s review another example to learn how well the website server software or CDN handles caching page resources. Caching page resources in the client browser or CDN layer offers an obvious way to improve page load time. However, web server software needs to be properly configured to handle this correctly.
If a page has been visited before, and the page resources are cached, Chrome sends conditional web requests to avoid refetching them each time.
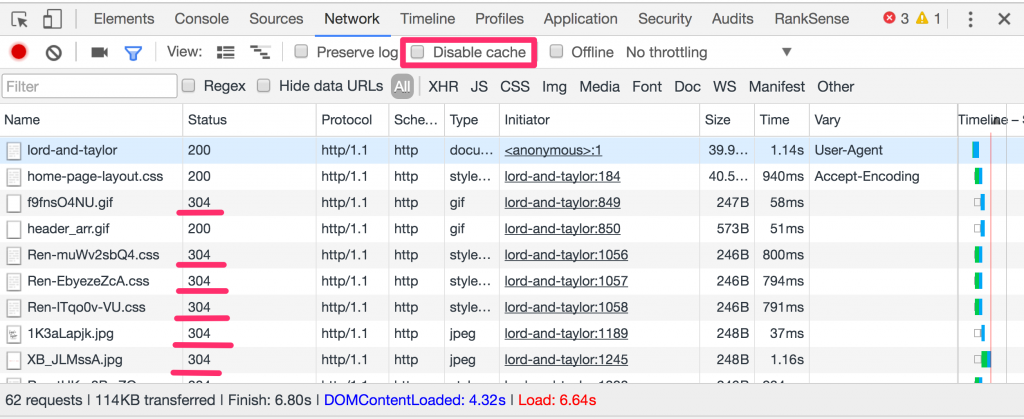
You can see page resources already cached by looking for ones with the status code 304, which means that they haven’t changed on the server. The web server only sends headers in this case, saving valuable bandwidth and page load time.
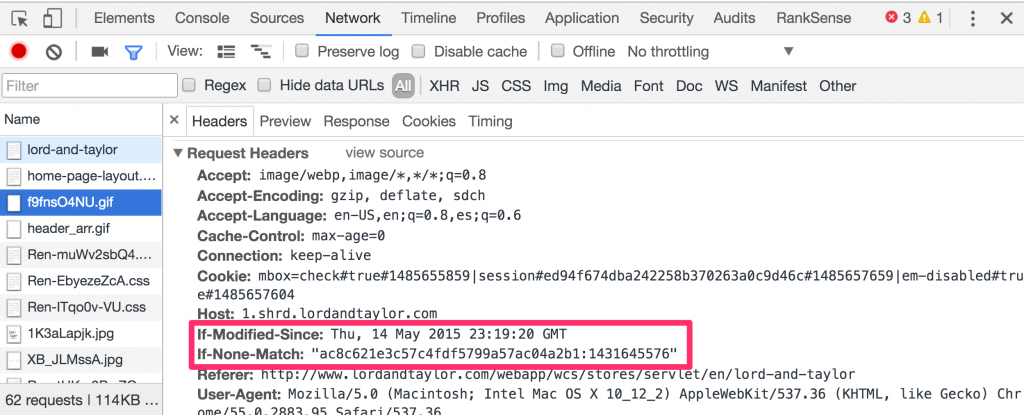
The conditional requests are controlled by the IF-Modified-Since request header. When you tick the option in DevTools to disable the cache, Chrome doesn’t send this extra header, and you won’t see any 304 status code in the responses.
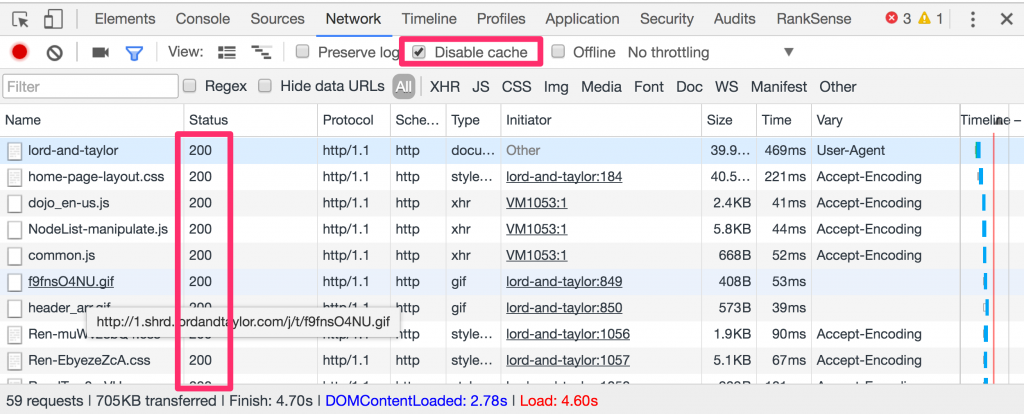
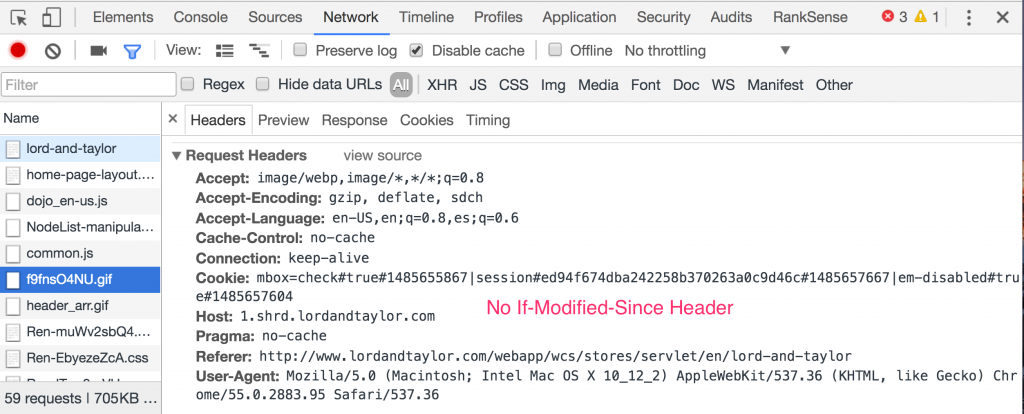
This is particularly handy to help troubleshoot page resource changes that users report are not visible.
Finally, it is generally hard to reproduce individual users’ performance problems because there are way too many factors that impact page load time outside of just the coding of the web page.
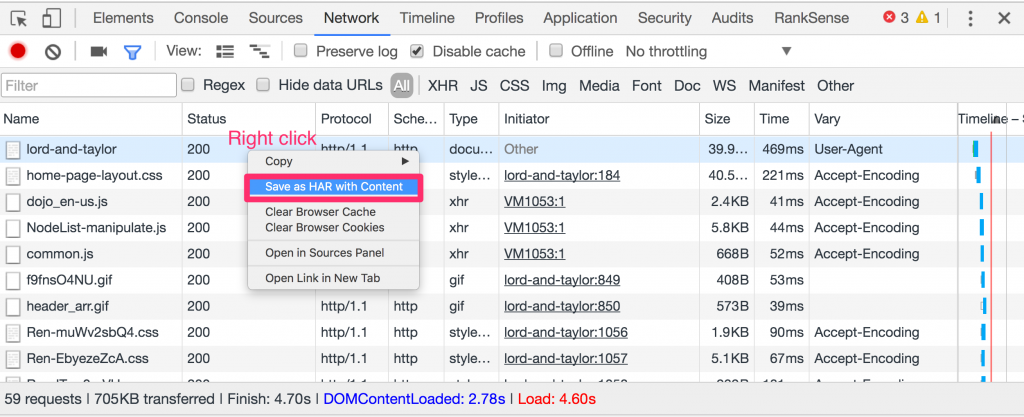
One way to easily reproduce performance problems is to have users preserve the network log and export the entries in the log as an HAR file. You can learn more about this in this video from Google Developers https://www.youtube.com/watch?v=FmsLJHikRf8.
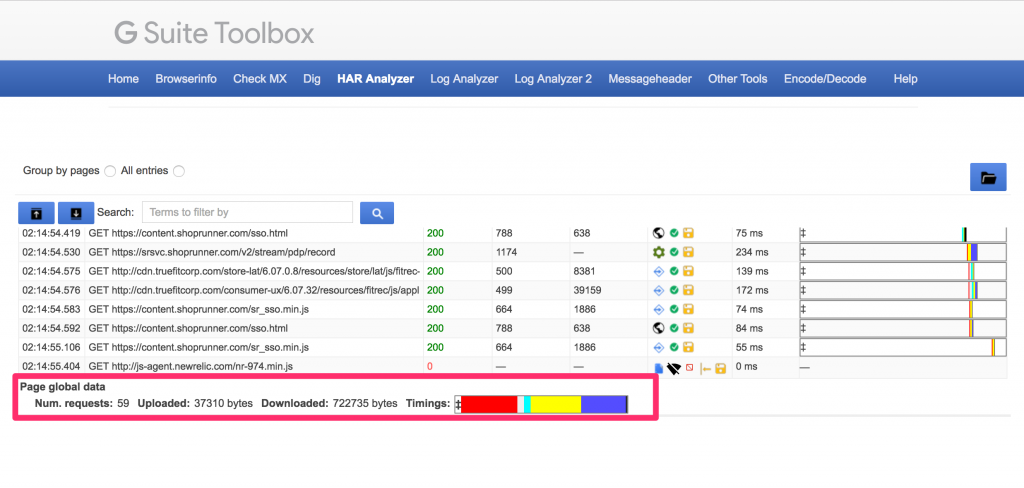
Google provides a web tool you can use to review HAR files you receive from users here https://toolbox.googleapps.com/apps/har_analyzer/. Make sure to warn users about saving potentially sensitive information in this file.
Bonus: Find mixed http and https content quickly
Aleyda mentioned using DevTools to check for mixed http and https content raising warnings in your browser. Here is a shortcut to identify the problematic resources quickly.
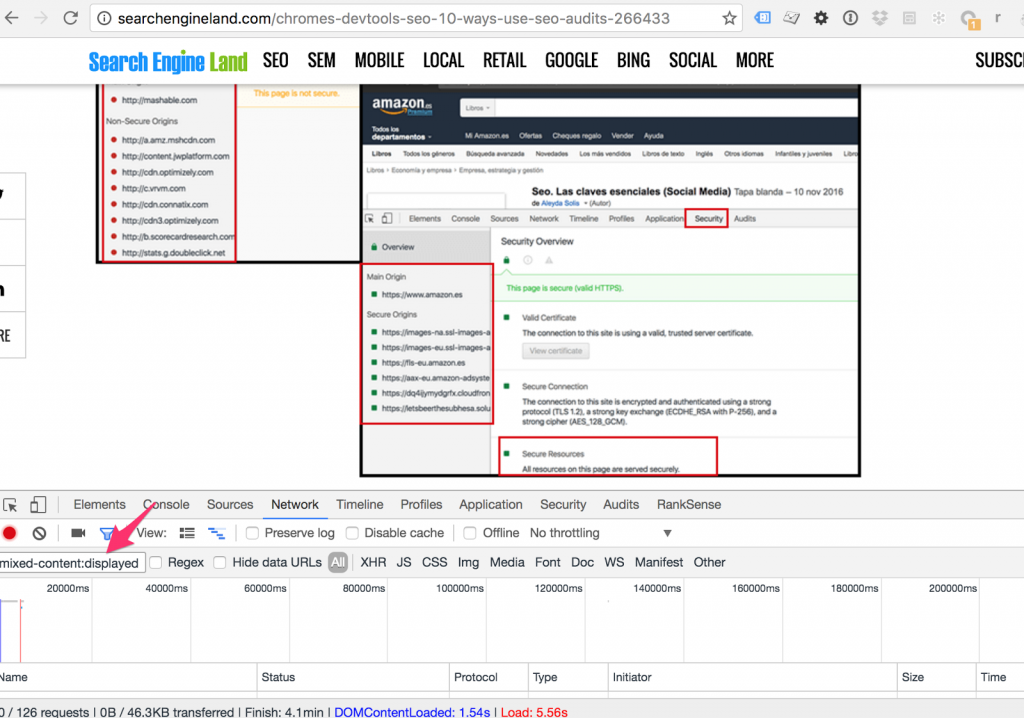
You can type “mixed-content:displayed” in the filter to get the resources without https.
If you are not actively using DevTools in your SEO audits, these extra tips encourage you to get started. And, if you are, please feel free to share any cool tips you might have discovered yourself.