By submitting your email address, you agree to receive follow up emails about RankSense’s products and services. You can opt out at any time by clicking the link in the footer of our emails. We share your information with our customer relationship management partners. For information about our privacy practices, please see our privacy policy
Doing More with Less: Automated, High-Quality Content Generation
by Barbara Coelho | June 25, 2020 | 0 Comments
How many times have you been writing in a Google Doc or in Gmail and Google automatically completes your sentence?
These surprisingly accurate suggestions are already leveraging AI and automation into your SEO work without you even realizing it.
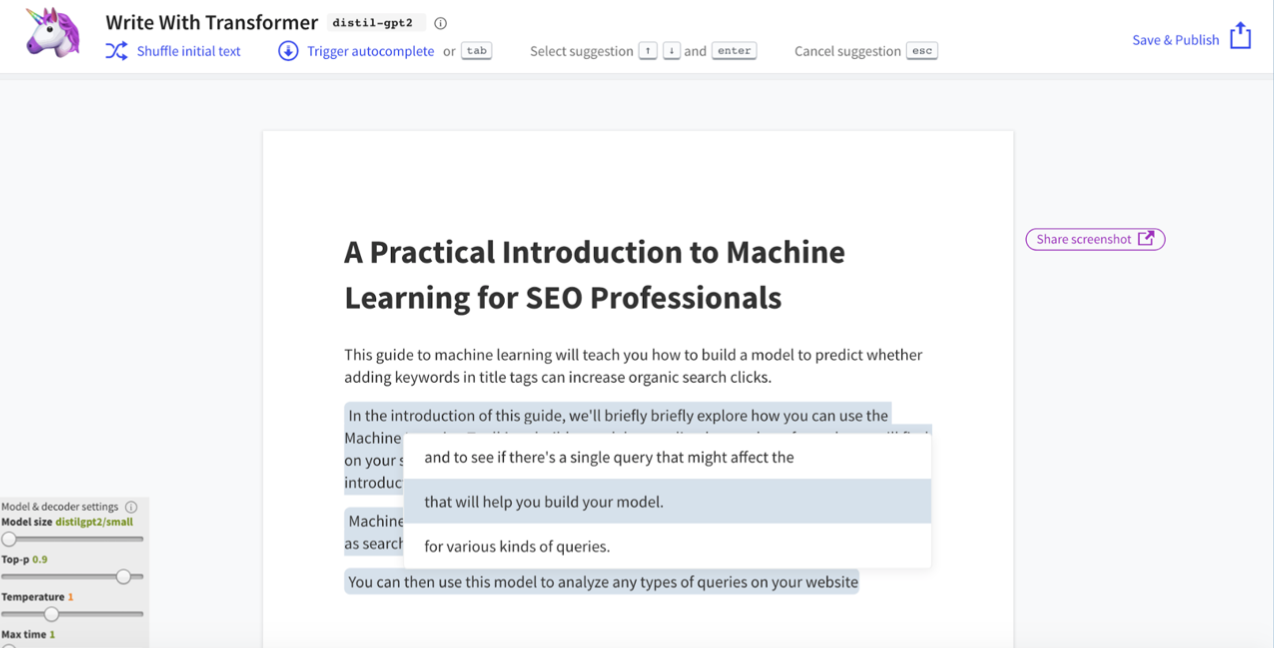
This advanced capability is freely available and accessible. For example, Write with Transformer is a tool that can automatically generate content in a word document with just a simple title.
In the example below, Hamlet added the title of a previous article he wrote for SEJ and voila—full sentences were written by the computer just by hitting the tab key.
“We are in the era where intent-based searches are more important to us than pure volume.”
“You should take the extra step to learn the questions customers are asking and how they describe their problems.”
“Go from keywords to questions.”
What is the opportunity?
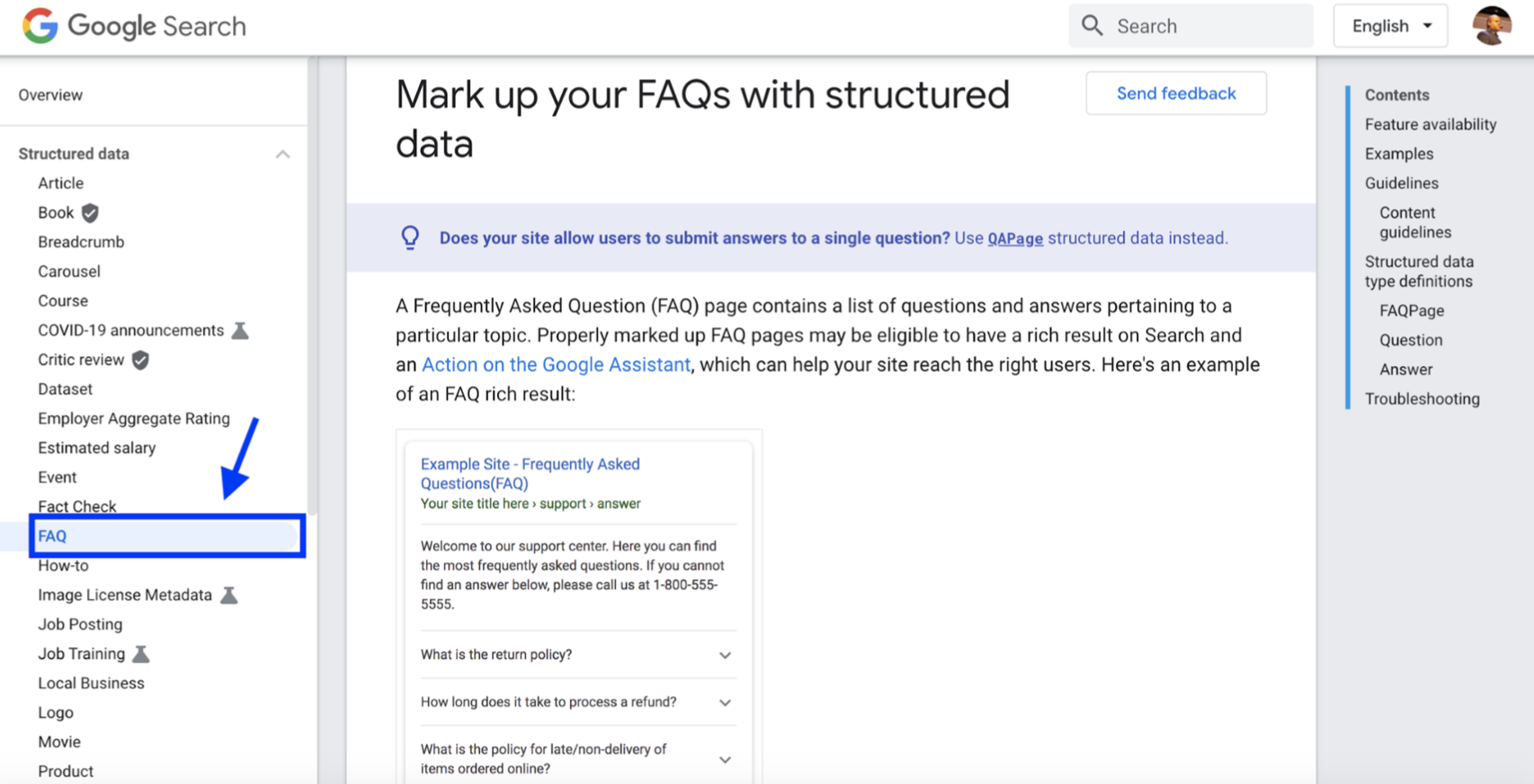
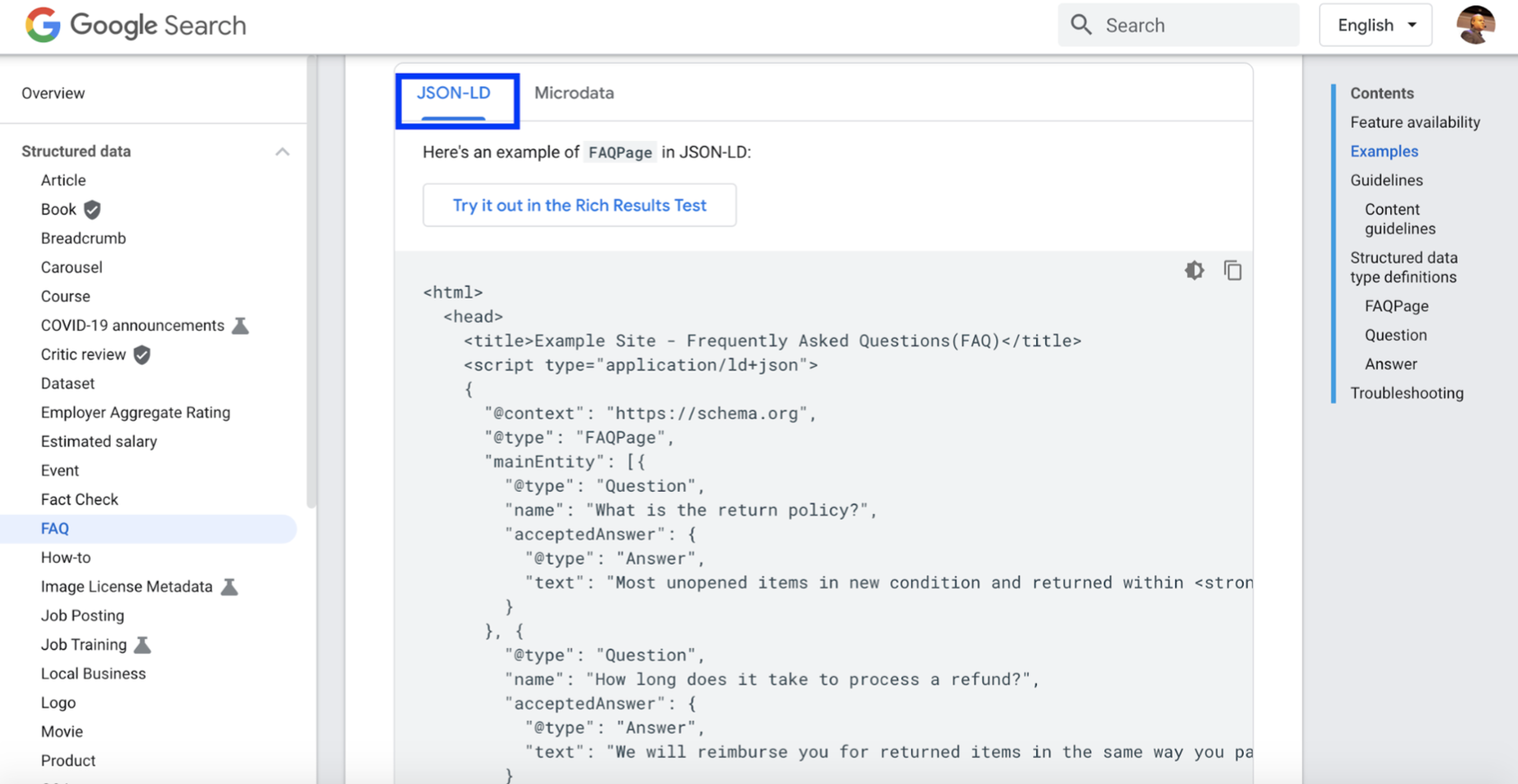
These days, it’s more valuable to think of search engines as answering engines. An effective way to write original, popular content is by answering your target audience’s most important questions.
Even better, FAQ search snippets take up more real estate on the SERP.
However, researching these questions and writing each and every answer manually is going to be expensive and time-consuming.
To get around this, we can automate it by leveraging new AI advancements and your existing content assets.
Leveraging Existing Knowledge
Most established businesses have valuable, proprietary knowledge bases that they have developed over time via interaction with customers, such as support emails, chats, internal wikis, etc.
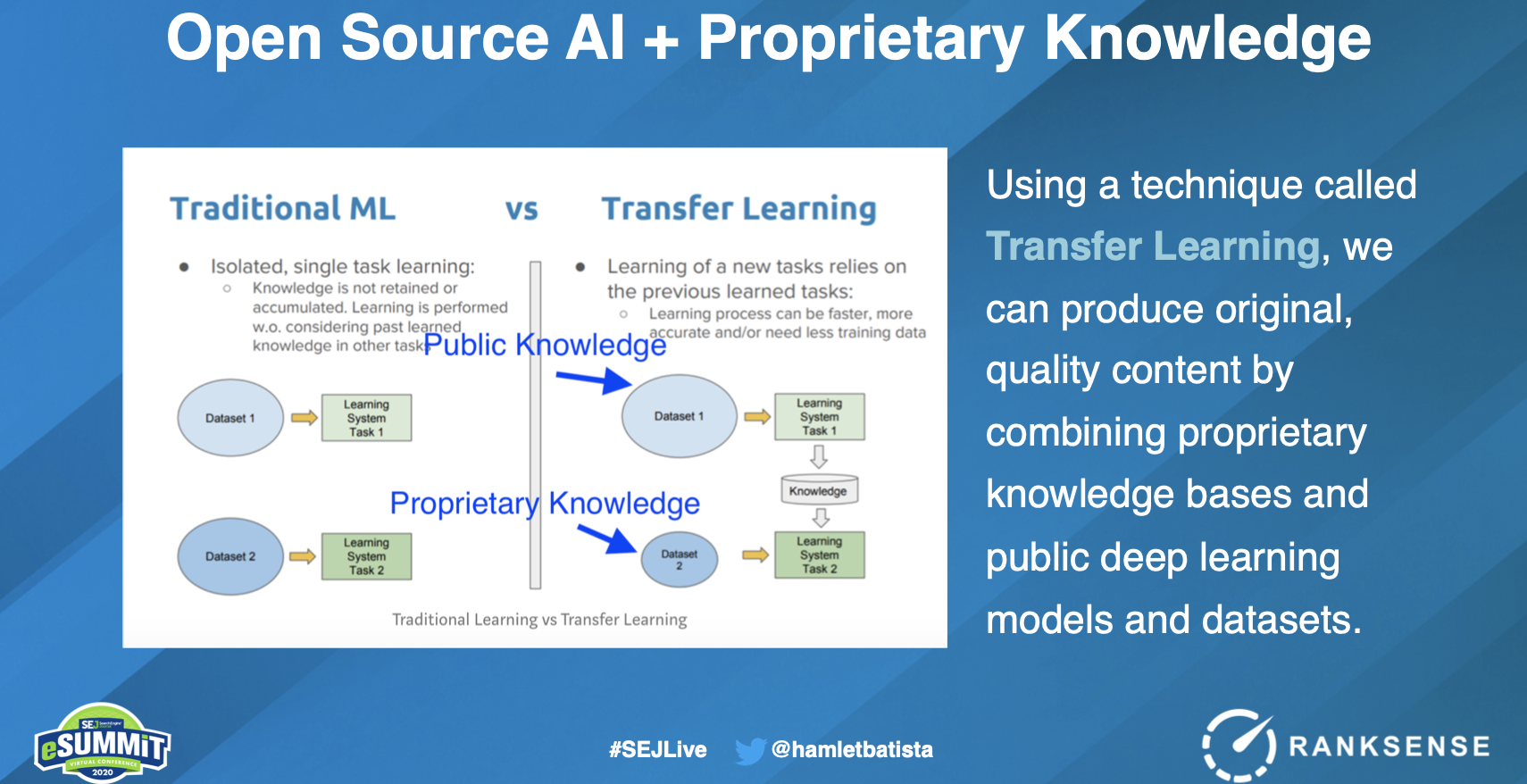
You can leverage this proprietary knowledge with public algorithms and knowledge bases to produce original, quality content through a technique called Transfer Learning.
With traditional machine learning, you’re primarily leveraging existing knowledge to come up with predictions. With transfer learning, you can tap into common sense knowledge via public datasets that have been built over time by big companies like Google, Microsoft, Facebook, etc. and combine it with your proprietary knowledge.
The Plan
We will review automated question and answer generation approaches using these steps:
There are a number of tools available to find users’ popular questions, but here we will focus on three:
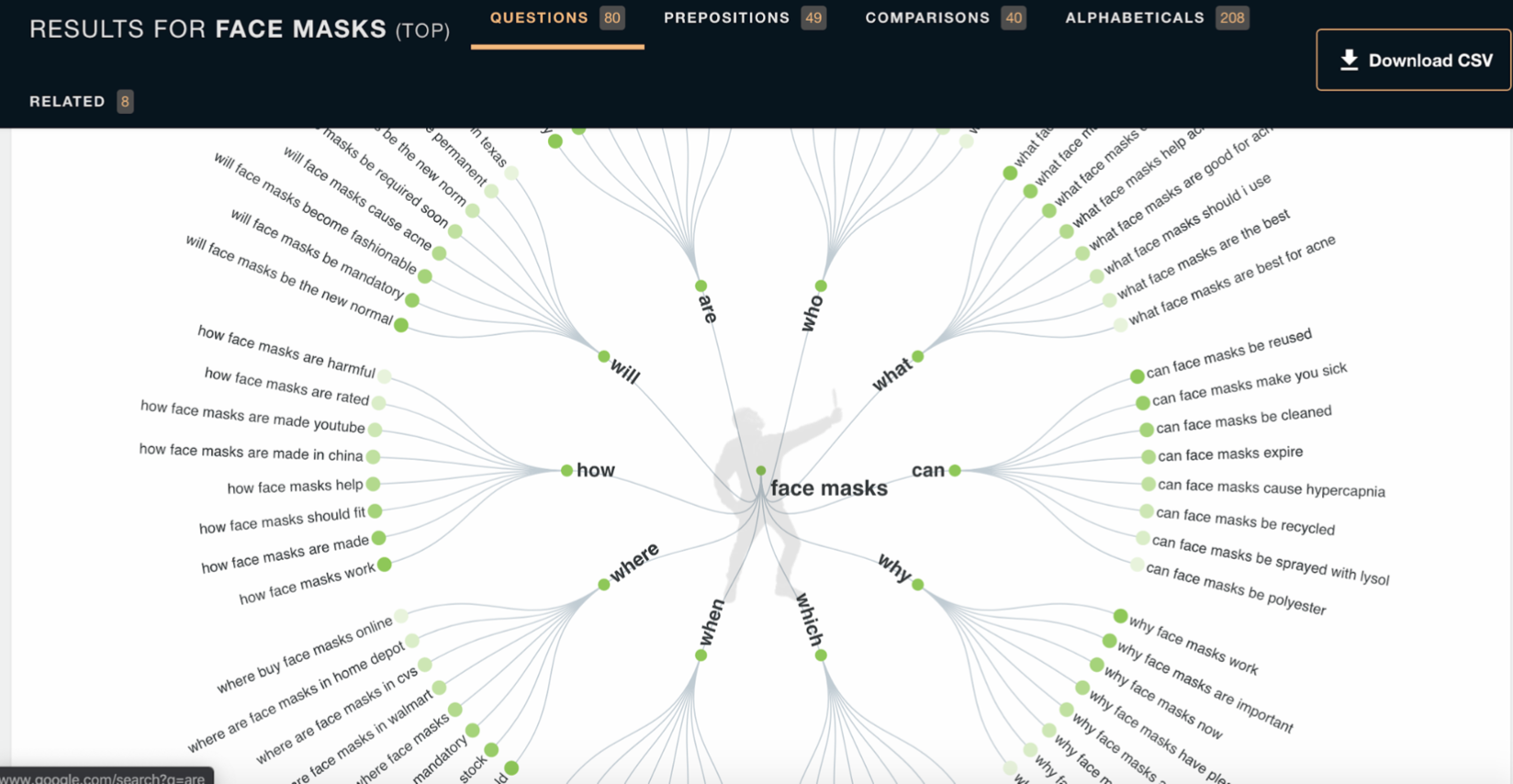
Answer the Public: Type in a keyword, in this case, “face masks,” and see common questions asked pertaining to the keyword
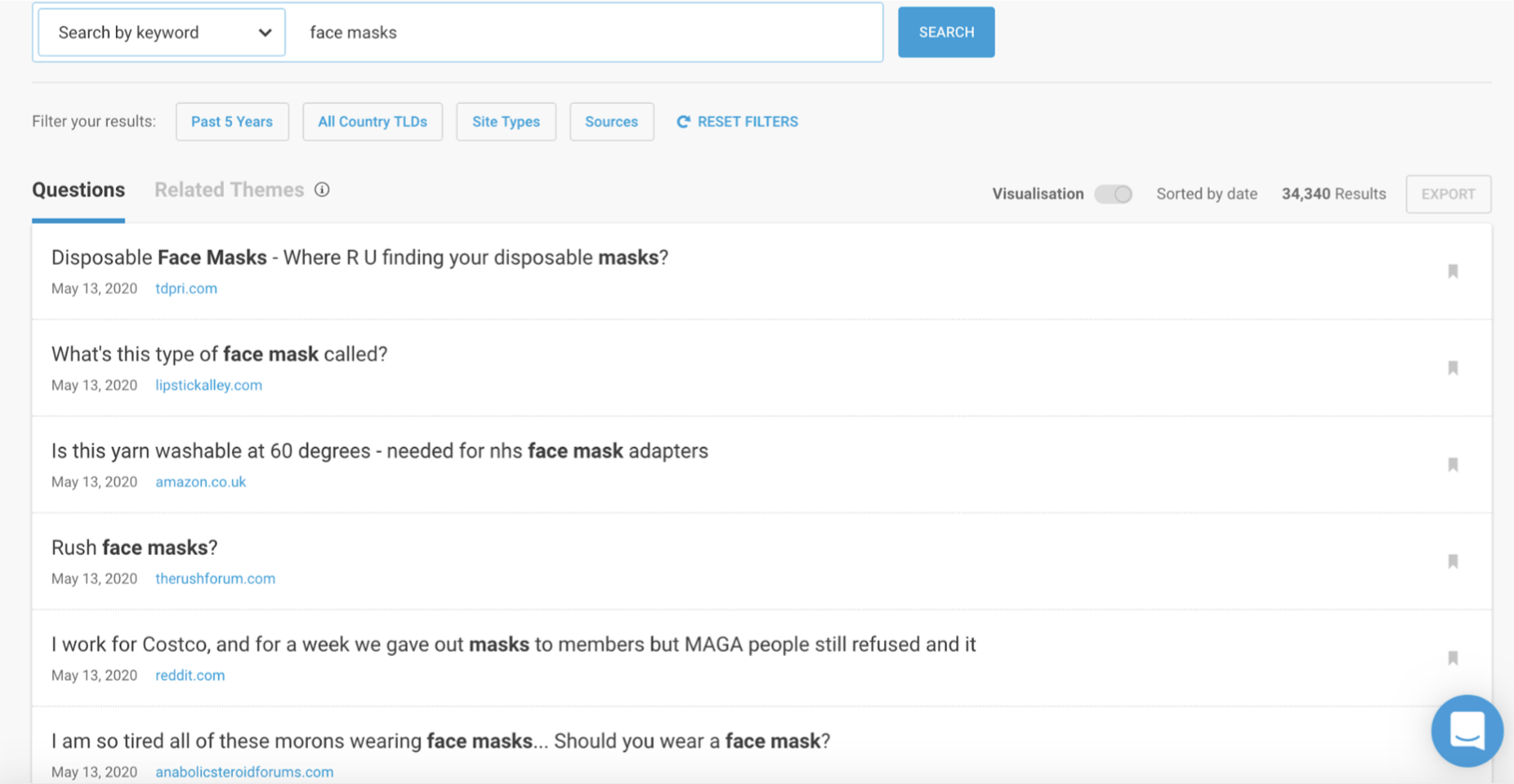
Question Analyzer by BuzzSumo: Collects aggregate information from forums and other resources to display long-tailed questions based on keyword entry
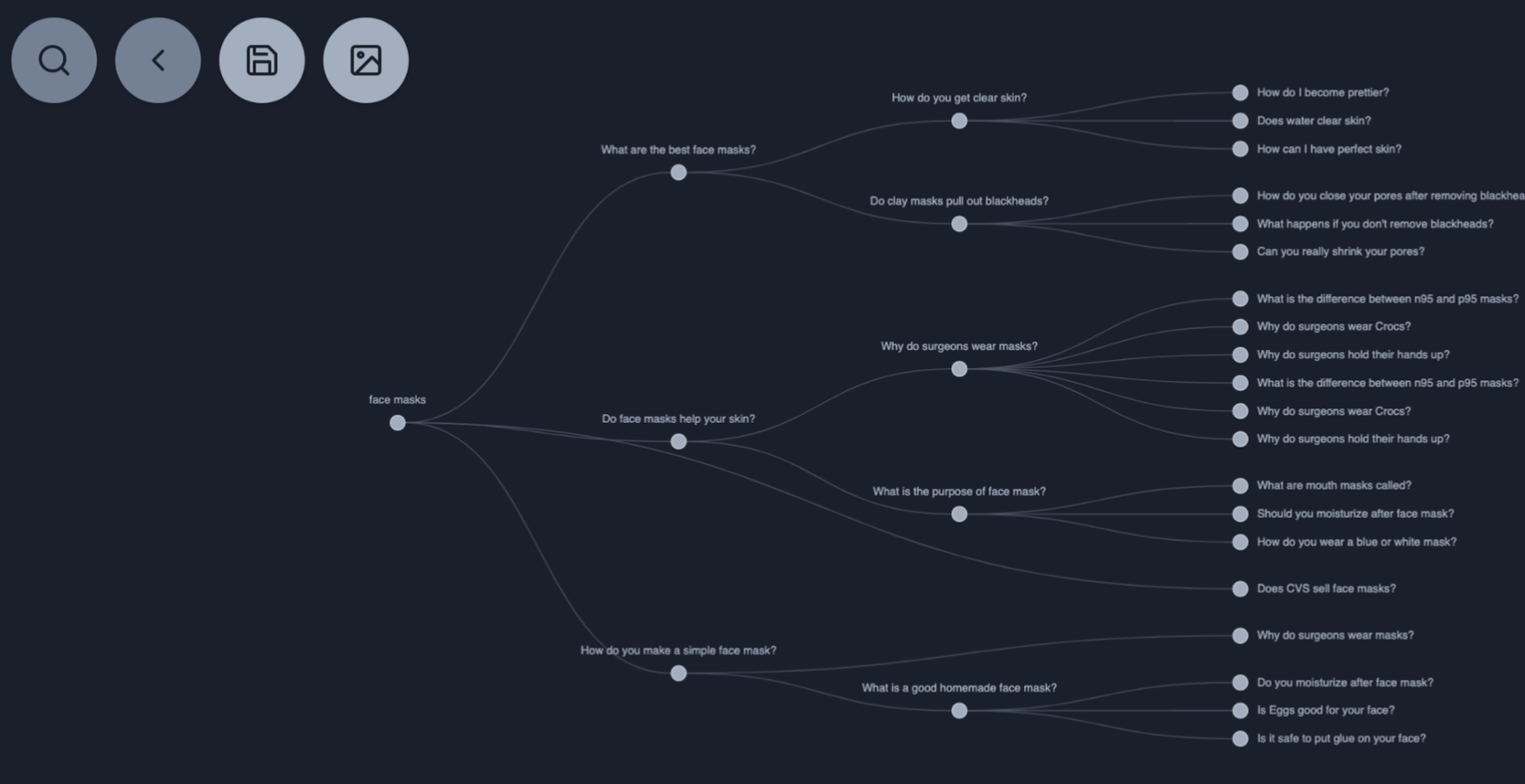
AlsoAsked.com: Scrapes queries from Google to create different questions
Essentially, finding popular questions based on keywords is not a challenge and can be done with free versions of tools used above.
Question and Answering System
Now let’s begin to put together a system to answer these questions.
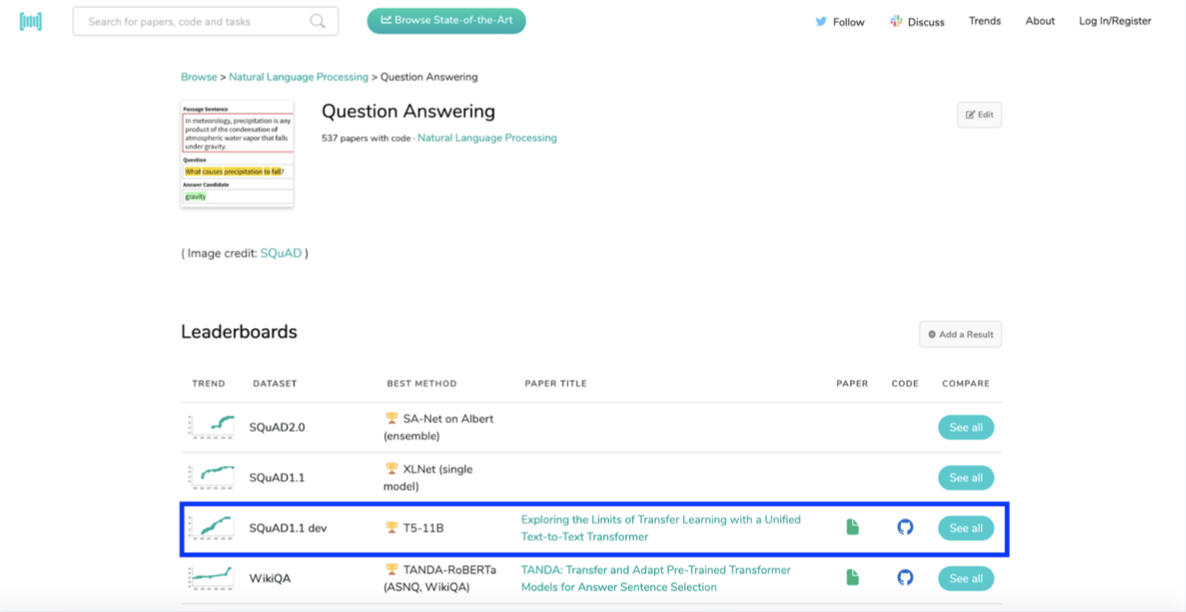
Papers with Code is a great resource to find code for this type of leading entry search. It allows you to tap into the latest, state-of-the-art research that is published for free by academics and researchers looking for feedback from their peers.
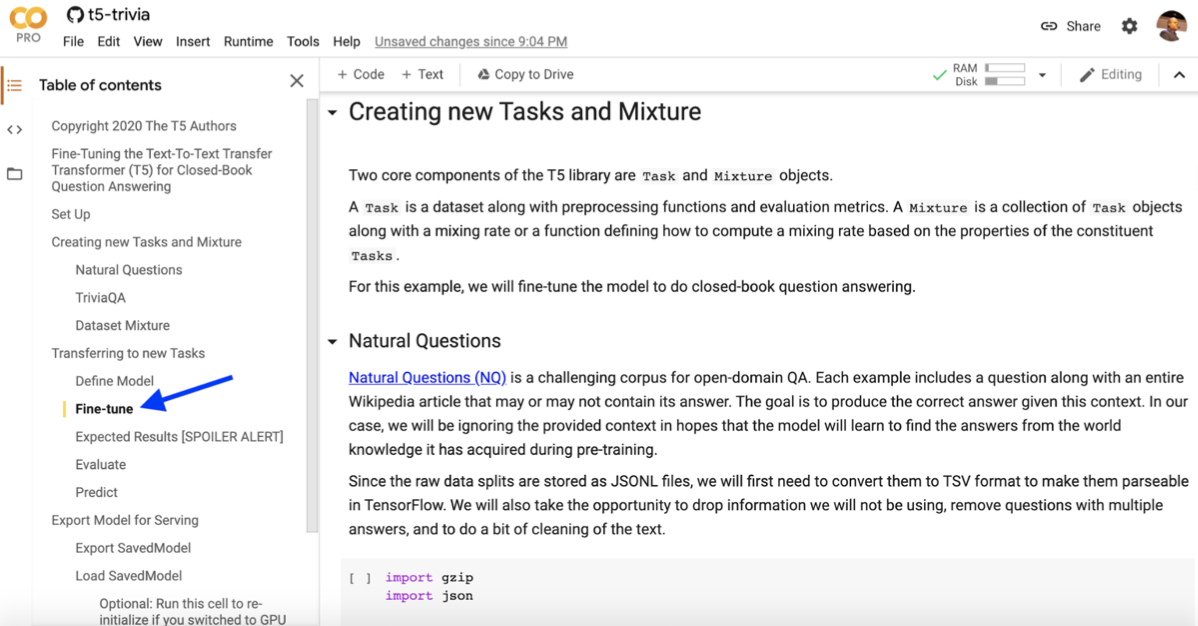
Question answering is an area of very active research and we can access the code to use ourselves. Here we will use T5, a model from Google.
With this model, we get the code (the free algorithm) needed to answer the questions, but we also need the training data (dataset) that the system will use to learn to answer questions.
Provide the question and context (content/text most likely includes the answer)
This is something you can type into a Colab Notebook and is fairly easy to do.
To get the context, use the requests HTML library to pull the URL. Provide a selector, a path to the element, and make the call to pull it and add it to the text.
The concept is that we’re asking a question in which we know where to find. By providing a direct URL to the source, the computer will return the answer.
Something a Bit More Ambitious
What happens when we don’t know where to find the answer?
The release of Google’s T5 and Microsoft’s TuringNG models have allowed for questions to be answered without providing any context at all. Both have the capability to pull answers based on what they’ve learned and been trained on.
The Google T5 team, made up of the geniuses who built the algorithms themselves, went head to head with their model in a closed book pub trivia challenge and lost!
Try it out for yourself and see if you can beat the model!
Let’s Train, Fine-tune and Leverage T5
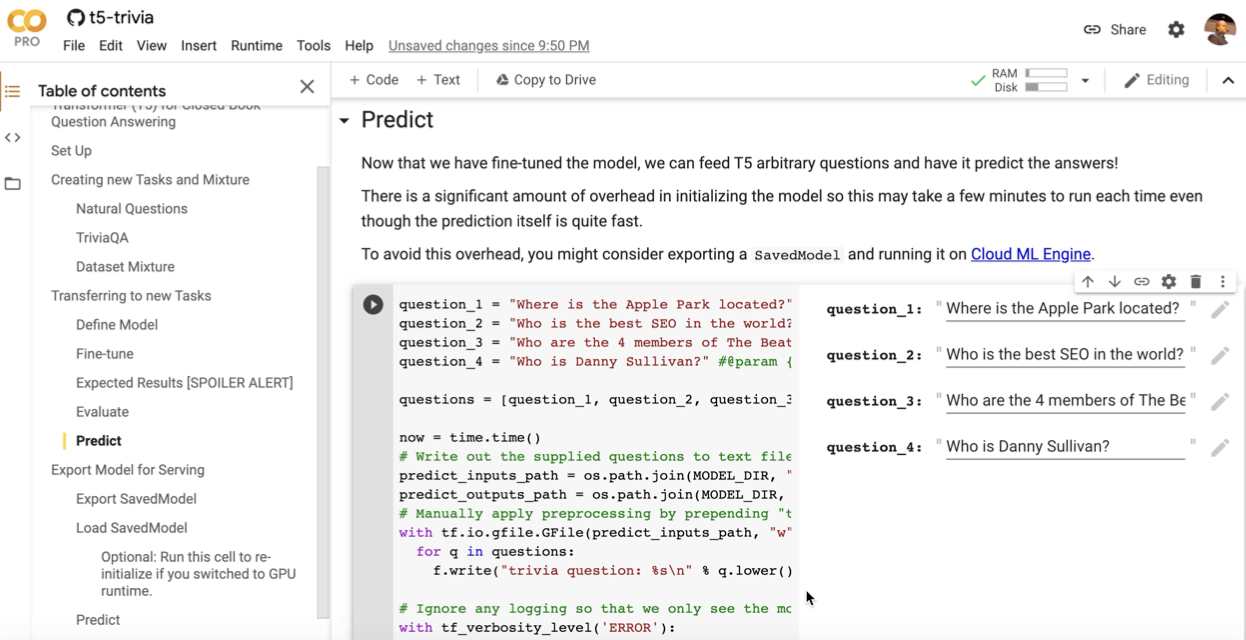
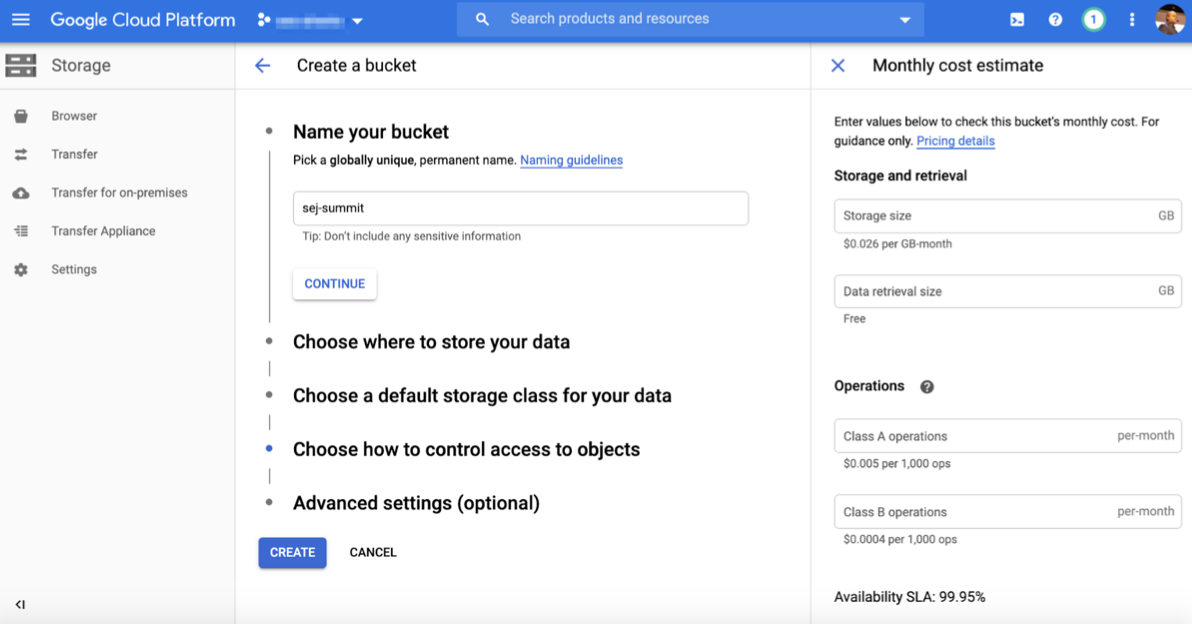
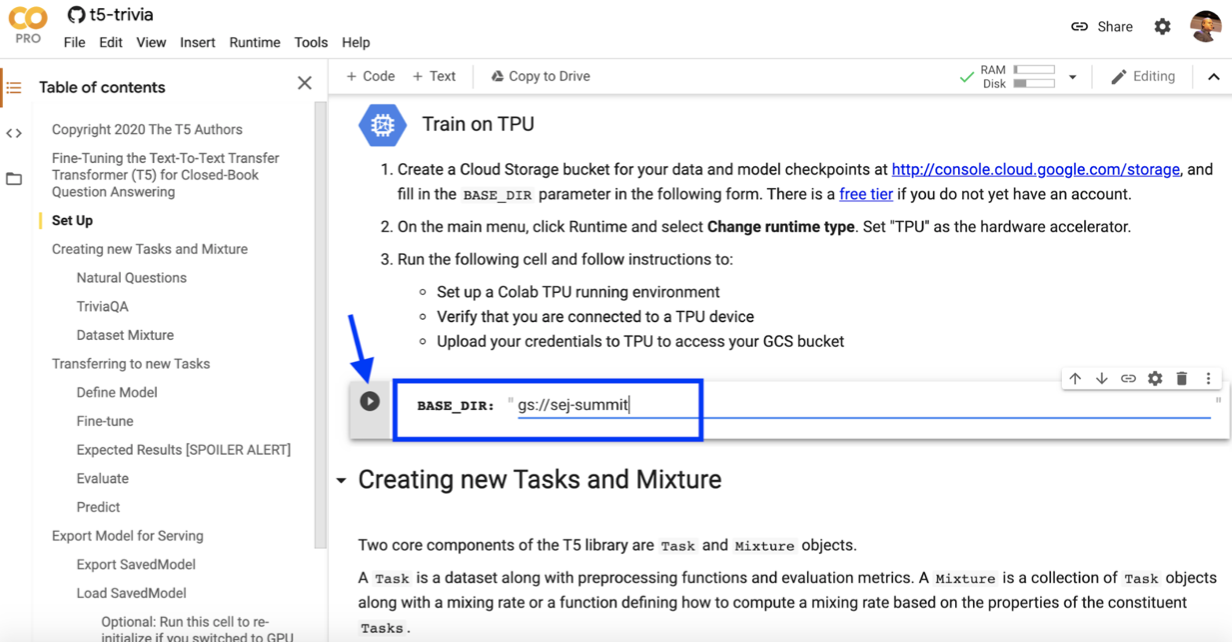
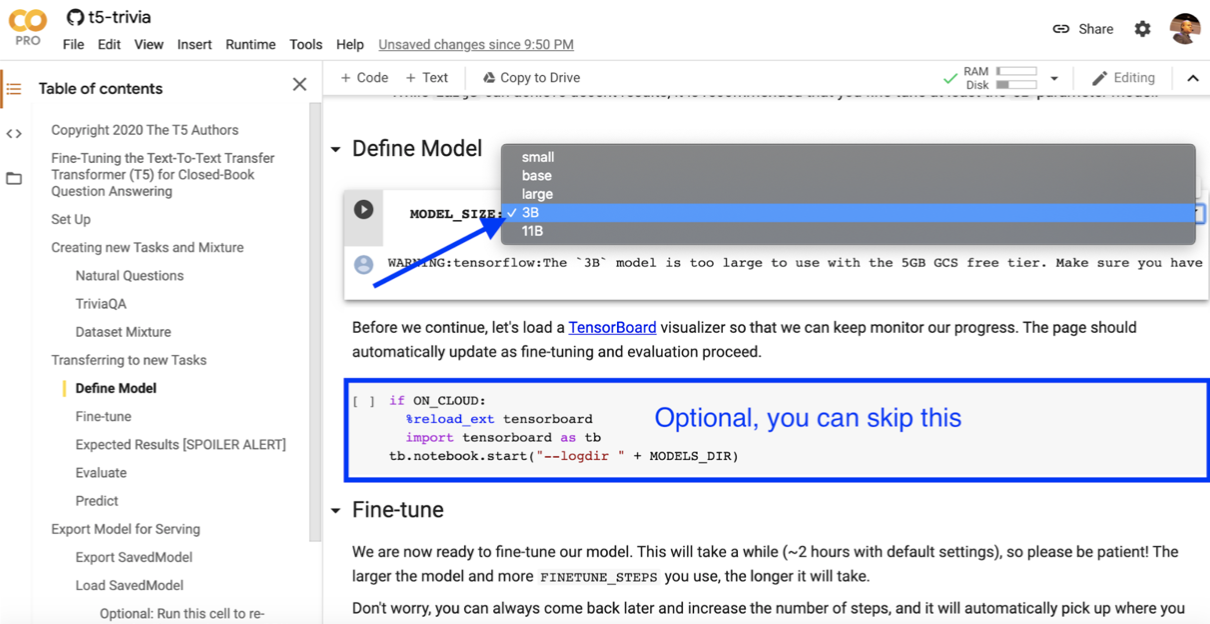
Now, we will train the 3-billion parameter model to answer our arbitrary questions using a free Google Colab with the TPU runtime.
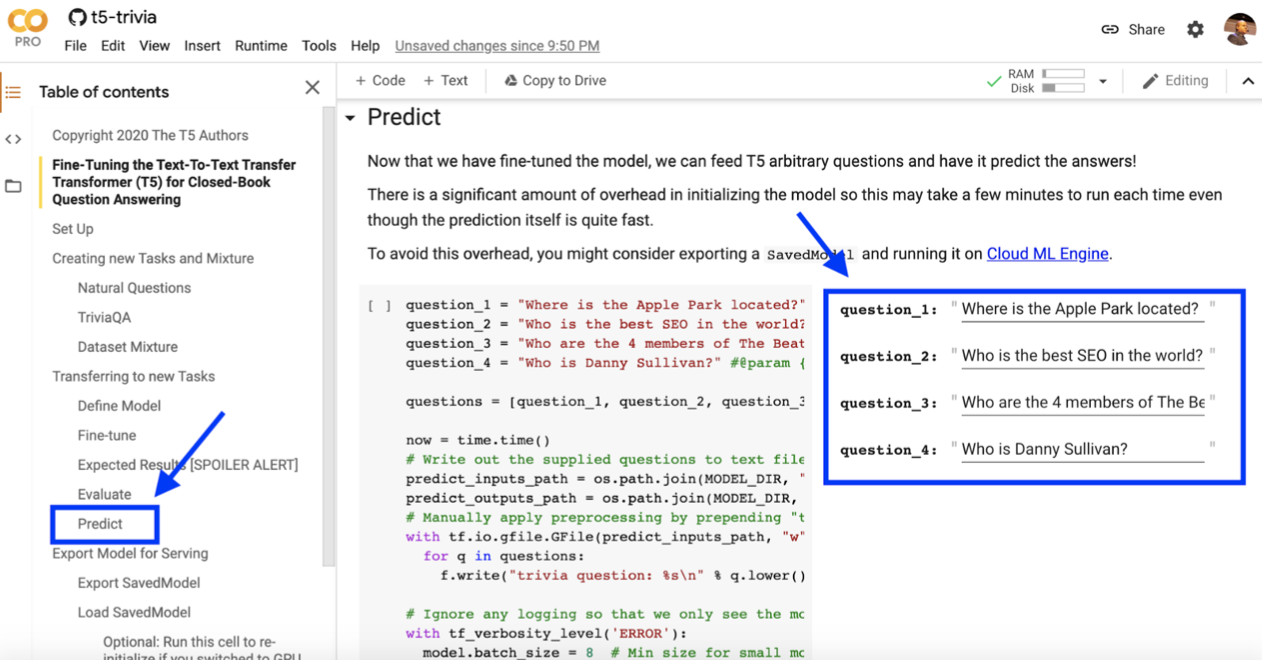
In this example we’ll ask the following questions:
Custom Python scripts are much more customizable than Excel spreadsheets. This is good news for SEOs — this can lead to optimization opportunities and low-hanging fruit. One way you can use Python to uncover these opportunities is by pairing it with natural language processing. This way, you can match how your audience searches with your...
As we continue to improve the RankSense app for Cloudflare, we are always working to make the app more intuitive and easy to use. I'm pleased to share that we have made significant changes to our SEO rules interface in the settings tab of our app. It is now easier to publish multiple rules sheets and to see which changes have not yet been published to production.
For the following Ranksense Webinar, we were joined by Antoine Eripret, who works at Liligo as an SEO lead. Liligo.com is a travel search engine which instantly searches all available flight, bus and train prices on an exhaustive number of travel sites such as online travel agencies, major and low-cost airlines and tour-operators. In this...

 The Plan
The Plan