By submitting your email address, you agree to receive follow up emails about RankSense’s products and services. You can opt out at any time by clicking the link in the footer of our emails. We share your information with our customer relationship management partners. For information about our privacy practices, please see our privacy policy
Webinar Recap: How to Test robots.txt Against XML Sitemaps URLs using Python
by Anirudh Tatavarthi | August 18, 2020 | 0 Comments
For the following RankSense webinar, we were joined by Elias Dabbas, the owner of The Media Supermarket, here to run us through his Python script for testing robots.txt. Elias takes us through his programming journey as a marketer, detailing the key struggles and his takeaways. He also provides a lot of insight into his script, describing how it can be used from a practical standpoint.
We would like to thank Elias for his fantastic presentation and his contribution to the RankSense Twittorial series. We would also like to thank anyone who attended the webinar live and as always, we hope you enjoyed it.
Here is a full recording of the webinar:
Here is the Colab notebook containing the script. (Click on Open in Colab)
During this webinar, Elias aims to educate marketers about the importance of programming and its helpful applications in the marketing world and showcase his code, making it easy for marketers, who are new to programming, to understand.
Elias Dabbas Background and Data Science Journey
Elias started off by explaining how he got into Python and data science, coming from a marketing and sales background. His curiosity for Data Science sparked after hearing about the term many times in the past. After taking a couple of courses, Elias realized that there are many parallels between the marketing and engineering world. Upon learning that he could use Data Science to elevate his business, Elias motivated himself to spend the last 4-5 years learning how to code and even created his own Python library, now with over 90,000 downloads.
When asked how marketers can overcome their initial fear of programming, Elias explains that programming does not have to be as intense as software development. He expressed that after a few months of consistent coding, you can start becoming productive as a software user.
Elias’s biggest psychological roadblock he had to overcome as a marketer stepping into the programming world was learning how to deal with computers instead of people. He emphasized the fact that he had to be very precise when programming, in contrast to giving instructions to humans, who respond to emotions and carry out tasks with just an outline. Our CEO, Hamlet Batista, mentioned that his experience was the opposite, coming from an engineering background.
Motivating Factors and Reaching the “Breakthrough”
When asked how his productivity levels after embracing programming differed from his productivity prior, Elias revealed that he has seen a major change in his workflow and created the opportunity to service a wider range of clients. By cutting down the time to complete tedious tasks through scripts, Elias was able to serve these scripts to clients, bringing them great satisfaction and useful information. Upon realizing how powerful the blend of programming and marketing is, Elias was hooked and used this as motivation to create more.
Hamlet gave his take on the story through a simile, explaining that manual work is like walking while programming is more like riding a bicycle. Learning to ride a two-wheel vehicle may be an arduous task at first, but upon mastering it, you arrive at a realm of new possibilities.
Elias emphasized practice, saying that you should constantly use and refine your skills with any data you can until you reach a “breakthrough” point, where you resort to programming to solve problems of all types. Elias states that at this point, you reach a higher level of productivity and constantly learn about your programming language. Elias shared that the realization of doing real work through programming fueled his motivation.
Walking Through the Script
This script aims to clarify whether your robots.txt file is blocking any of the URLs in your XML Sitemap. Elias runs through the steps needed to successfully run the script:
The first block in Elias’s code installs advertools using the “!pip install” command. “%%capture” makes sure that the notebook does not show all of the output information from the download.
Next, Elias goes through the packages imported for the script. He emphasizes the importance of printing the versions of the packages you use as it allows users to identify problems that may occur due to a specific version.
Elias explains that every package has a “__name__” and “__version__” attribute, which he uses in combination with a “format string” to display the version numbers.
Next, Elias defines a variable named “robotstxt_url”, using this for the rest of the script. He uses a helpful tool available in Google Colab to define a variable using user input.
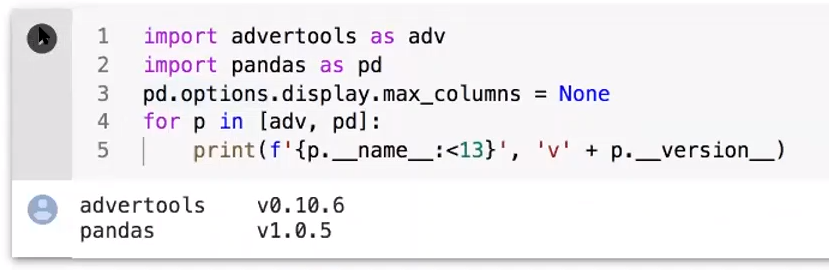
He then downloads the robots.txt file to a “df” which is a data frame. A data frame is a table of data with columns of the same type. Here is an example of the output:
As you can see, the table displays a lot of useful information, needed to keep track of progress and analyze the information.
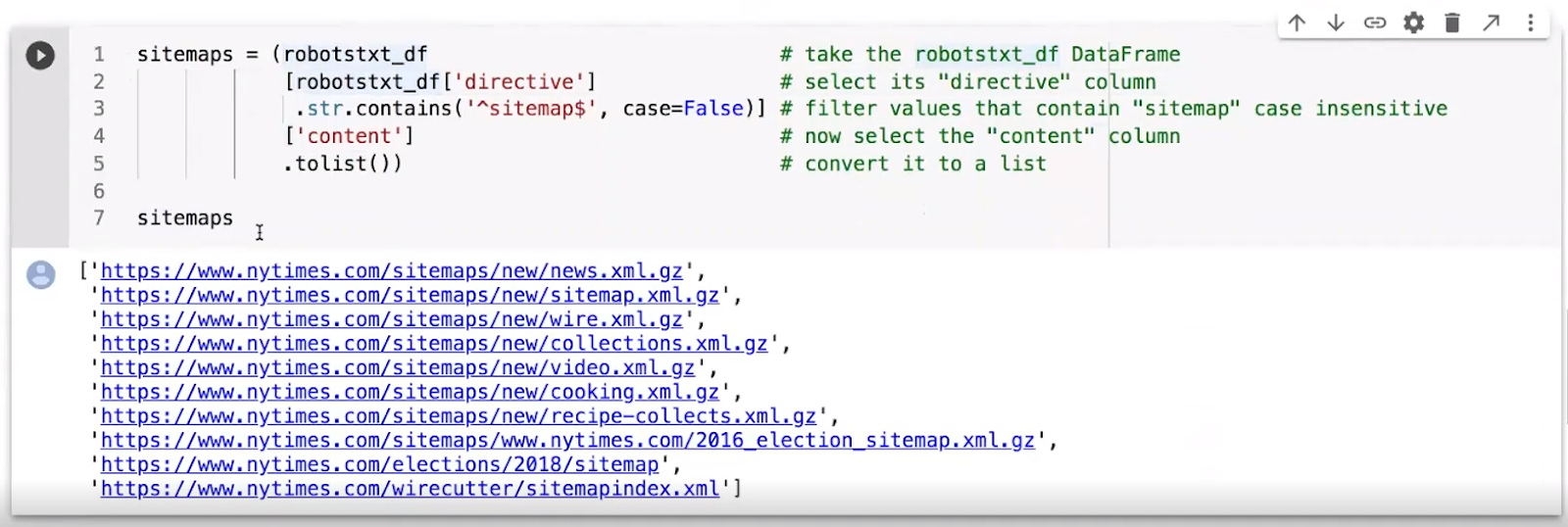
Next, Elias extracts the sitemaps from the robots.txt file. The block of code takes the data frame and extracts a subset of the data. The data is filtered for the sitemap and the content is gathered and converted to a list.
Elias defines another variable, “sitemap”, using user input from one of the extracted sitemaps.
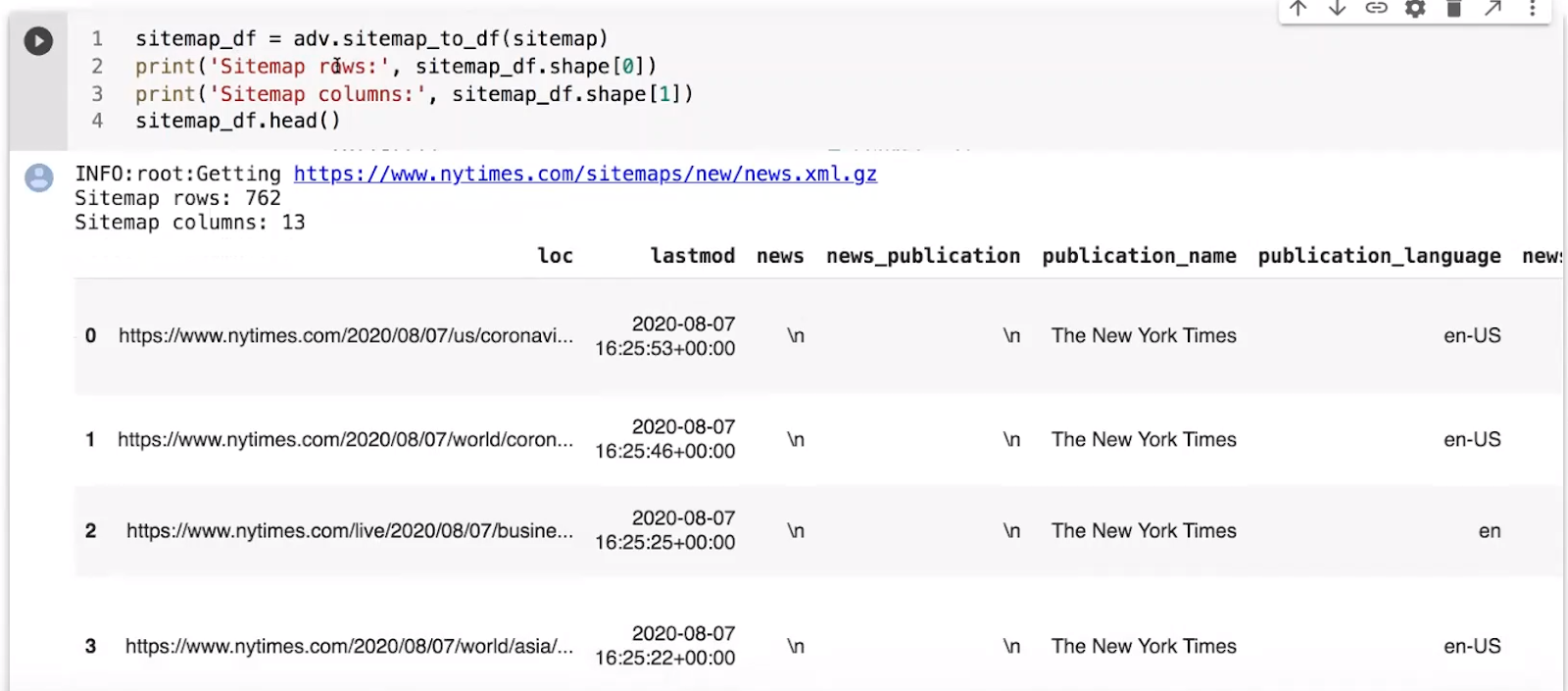
Now, Elias converts the sitemap to a data frame and displays the results.
The sitemap column is more useful when using a sitemap index, allowing us to determine which sitemap each one belongs to. The download date is helpful when tracking progress.
Next, Elias extracts the user-agents from the robots.txt file. It is very similar to extracting the sitemap from the robots.txt. The only difference is typing ‘user-agent’ instead of ‘^sitemap$’ in the contains method.
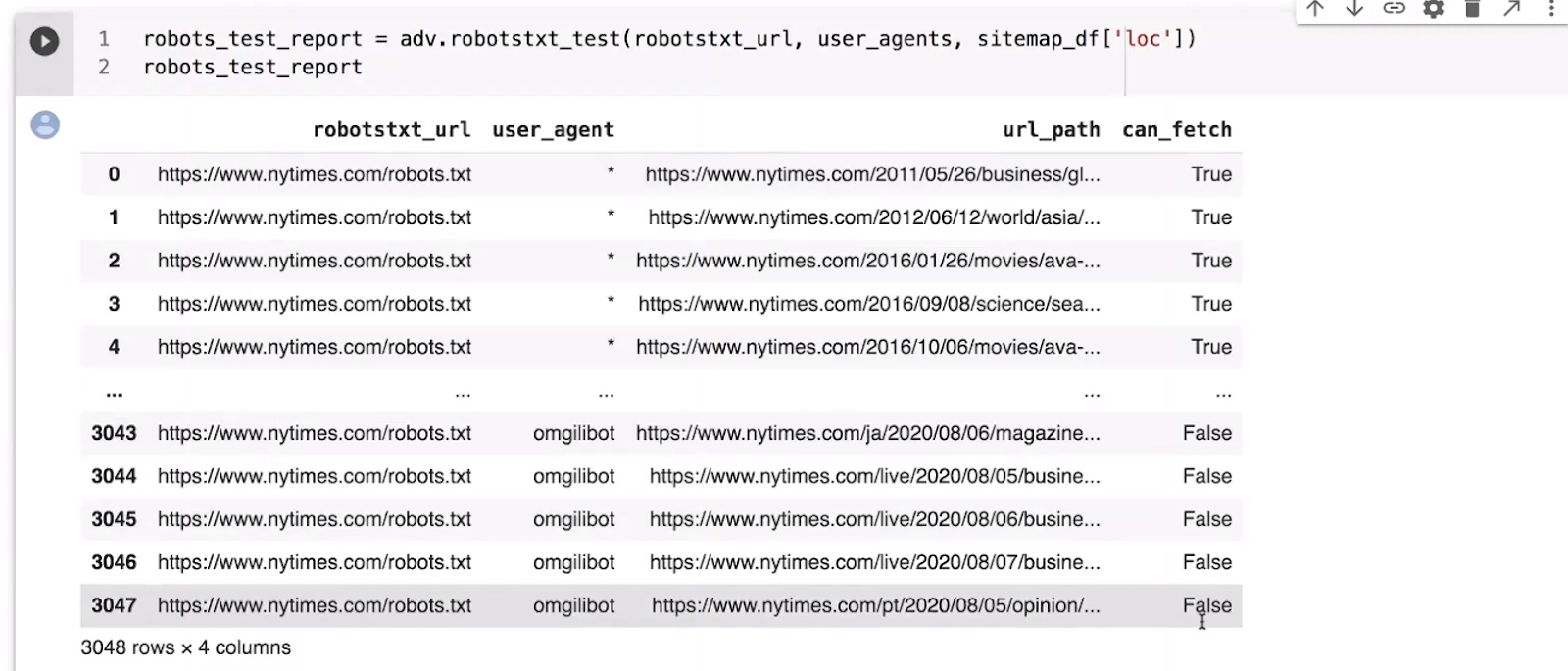
The last step of the script is to display the final report. The report checks whether each URL can be fetched by the specified user-agent.
Elias shows how you can easily alter the report to filter for “Googlebot” with one simple line of code. If any of the URLs display “False” for can_fetch, you can identify this as a problematic URL.
Elias emphasizes that this script is great for large scale testing as it would be very tedious to perform this study manually.
Answering the Homework Question
During this section of the webinar, Elias teaches us how to complete the homework assigned at the end of the Colab notebook. If you are interested in this script and would like to complete the homework by yourself, you may skip this portion of the recap.
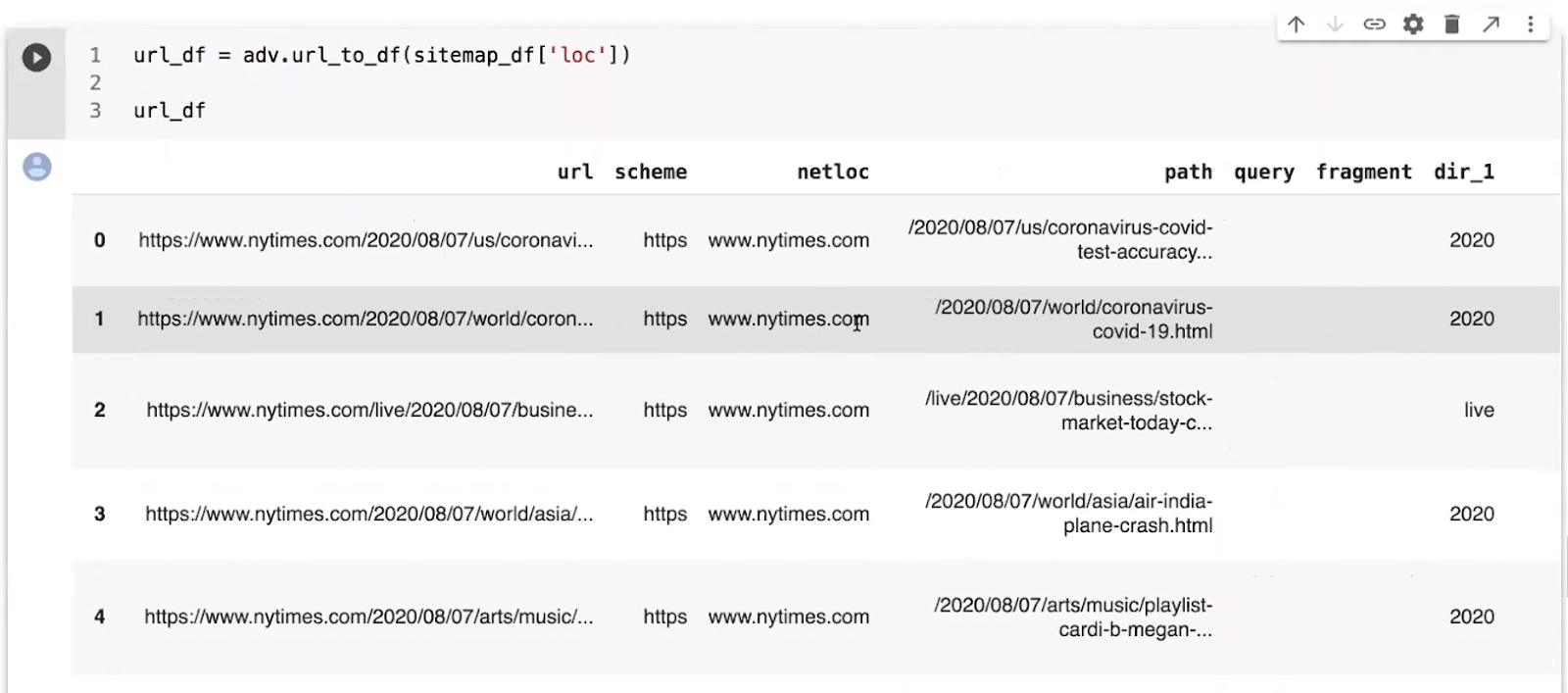
To solve the homework, first, Elias creates a URL data frame.
In this data frame, the metadata of the URL is split into many categories. Elias mentions that not all of the metadata is necessarily related to the topic of the article. This can be great when analyzing keywords.
Elias reveals that you can even analyze these URLs through the content category (ex: US, World, Business, Asia, Music, etc.). This helps in figuring out what the content on the URL is about. Elias says that a more interesting approach is to filter out articles with specific content categories to find “clusters” within those categories. This can be used to compare different categories.
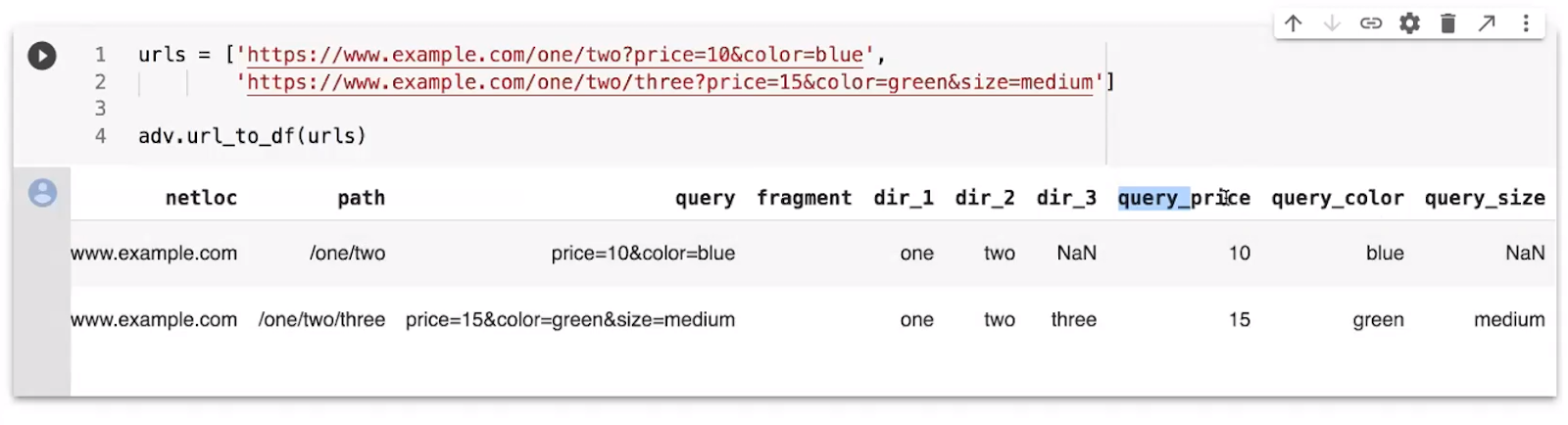
Elias writes another block of code, showing how you can study the different queries and parameters contained in a URL.
Hamlet describes these commands as “Excel on steroids” since these programs are doing advanced calculations and organizations, more efficiently.
For his final demonstration, Elias shows us how he can use his script to identify which type of topics the New York Times has been posting about recently.
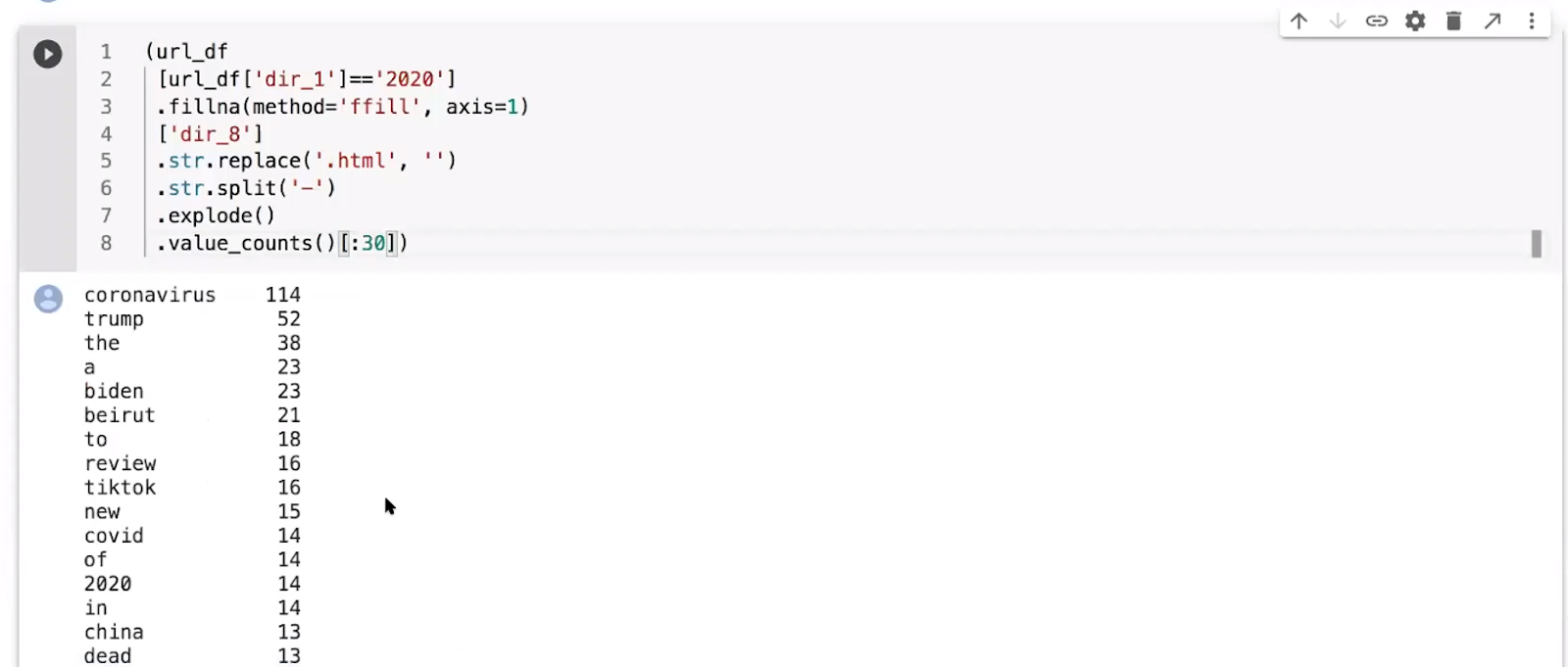
First, Elias creates a data frame holding the URLs and filters the data frame for articles posted in 2020. He points out that there are many keywords in the URLs of each article. To obtain these keywords visibly, Elias removes the .html at the end of each URL and splits the words by “-”. In the end, we are left with a list of keywords with the count of how many times they have appeared in recent articles. This is a great example of data journalism.
Closing Remarks
Once again, we would like to thank Elias Dabbas for the informative presentation. If you would like to contact him, you can do so on Twitter @eliasdabbas. Elias’s notebook is on GitHub for anyone to leave any questions or suggestions. Be sure to visit @RankSense on Twitter for new updates on upcoming events.
Custom Python scripts are much more customizable than Excel spreadsheets. This is good news for SEOs — this can lead to optimization opportunities and low-hanging fruit. One way you can use Python to uncover these opportunities is by pairing it with natural language processing. This way, you can match how your audience searches with your...
As we continue to improve the RankSense app for Cloudflare, we are always working to make the app more intuitive and easy to use. I'm pleased to share that we have made significant changes to our SEO rules interface in the settings tab of our app. It is now easier to publish multiple rules sheets and to see which changes have not yet been published to production.
For the following Ranksense Webinar, we were joined by Antoine Eripret, who works at Liligo as an SEO lead. Liligo.com is a travel search engine which instantly searches all available flight, bus and train prices on an exhaustive number of travel sites such as online travel agencies, major and low-cost airlines and tour-operators. In this...