By submitting your email address, you agree to receive follow up emails about RankSense’s products and services. You can opt out at any time by clicking the link in the footer of our emails. We share your information with our customer relationship management partners. For information about our privacy practices, please see our privacy policy
Programming can be thought of as a communication vehicle among ourselves, developers, and computers to solve difficult problems, but oftentimes we outsource our coding needs.
Why would we want to code if we can hire someone to do it for us? In reality, coding is not just an extra skill to have under your belt; it is a powerful tool that can open the door to endless possibilities. Lacking programming skills can actually become a constraint, as can poor vision.
For Hamlet, it wasn’t until his late 20s until he realized he needed glasses. When he finally got a pair, he was awestruck—Hamlet couldn’t believe he was missing out on crisp, clear, vision that entire time.
Coding is the same way—you don’t know what you’re missing until you learn how to do it. Not only will you be able to see problems in a new light, but you’ll also spot multiple ways to solve them.
Another advantage of learning this skill is the ability to bring in new perspectives to developers, who can, without a doubt, produce error-free code, but may sometimes hit a wall when they face a tough problem.
In this context, you can bring in new, fresh ideas to the table that can benefit your whole team.
Here we’ll be covering practical SEO applications of Python for:
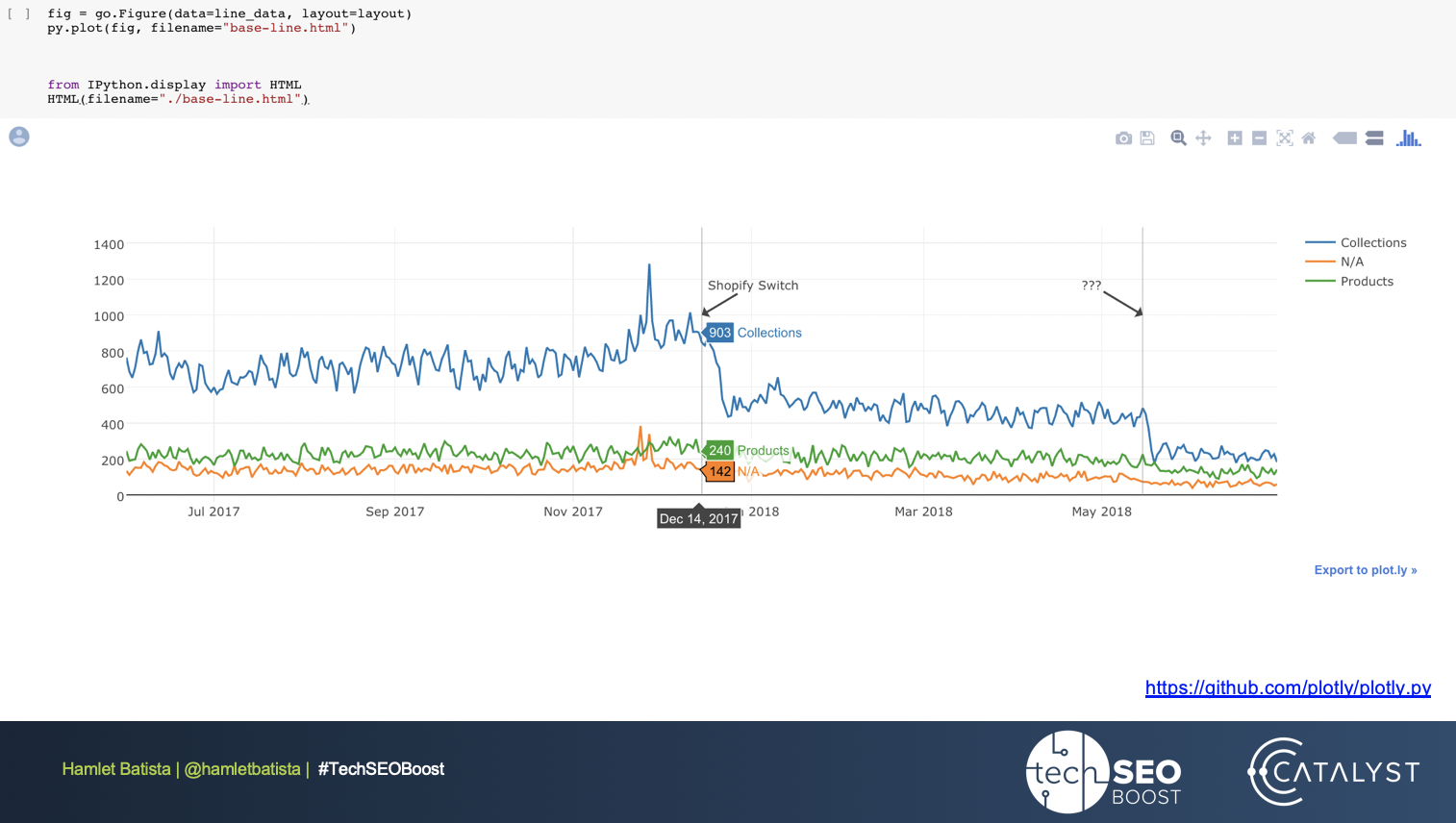
In this exercise, Hamlet focuses on a recent experience he had where a client moved from Ecommerce V3 to Shopify. Below is the exercise’s output, where you can pinpoint the problem and which pages were affected by it.
Solution Part 1
The first step in this phase is to pull the data from Google Analytics. One thing to take into consideration when pulling the URL from Google Query Explorer is the tokens, which allow the authorization to take place and expire in about an hour. A limitation of solely using the query explorer is that you are limited to about 10,000 requests, so this code will allow you to build a powerful data frame by iterating and paginating through the set to build it out completely, making it much simpler on the user side.
Next, we will store the data in a Pandas data frame.
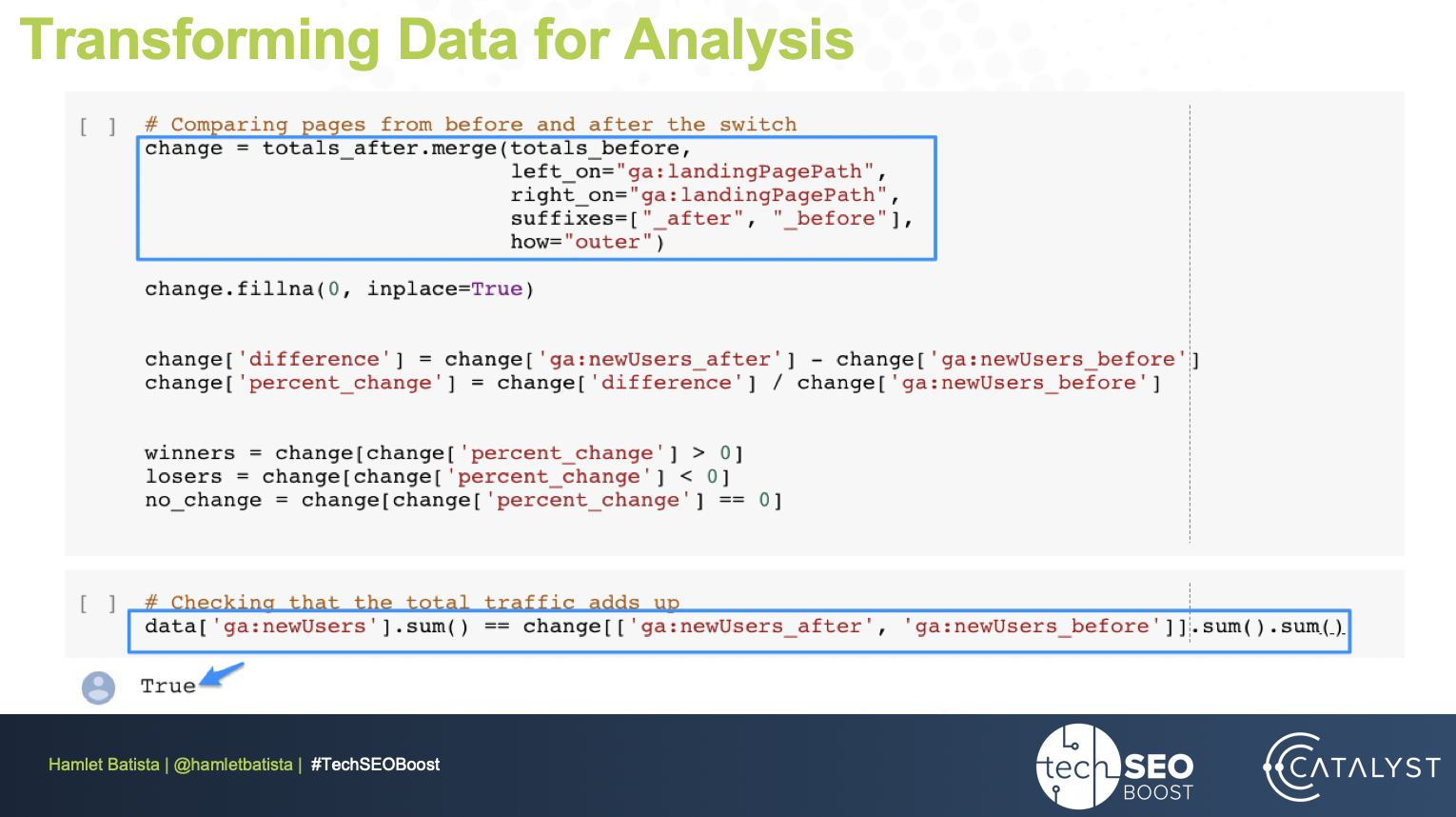
We will follow up by performing an analysis to isolate the pages that lost traffic, similarly to the way joins are used in SQL databases. Using an outer join, we can analyze the data by how many new users visited each page:
difference > 0, winners
difference = 0, no change
difference < 0, losers
Since it may be very easy to make mistakes, Hamlet added a line of code to ensure that the totals add up.
Now here’s the results, a reflection of all your time and hard work. Pandas also makes it easy to export this data into csv and excel files.
Solution Part 2
In this phase, we’ll focus on getting more useful output by determining the types of pages that lost traffic by using Regex. Since we moved from one platform to another where the URLs are completely different, we’ll have to crawl the original URL and compare it to the final URL, so that we’re comparing apples to apples.
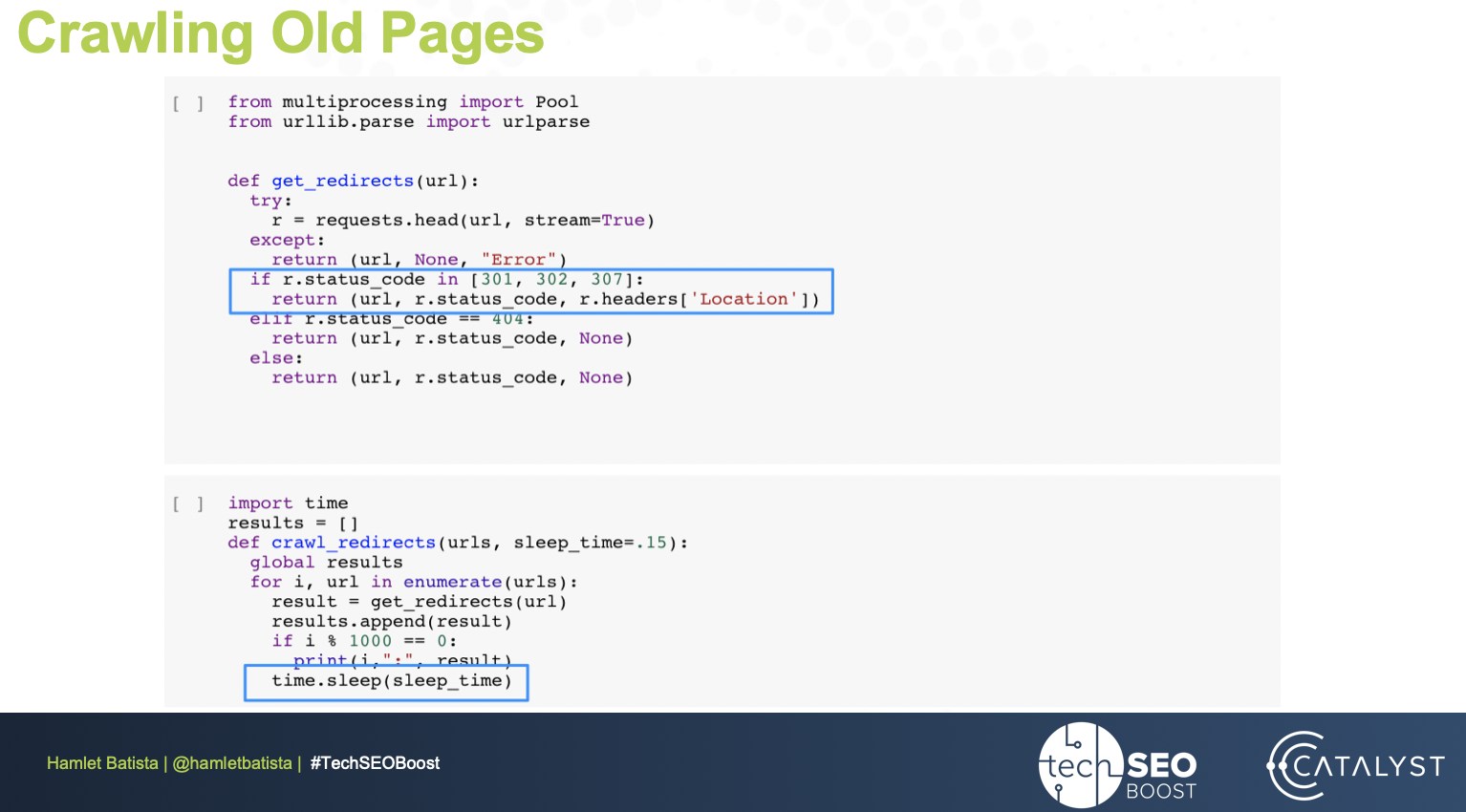
First, we’ll crawl old pages to follow redirects. It’s important here to make sure the status code is within 301, 302, 307, as sometimes checking 300-399 will fail since some 300 codes (such as 304) have a completely different meaning. Adding sleep will ensure you stay on good terms with the developers since you’re taking the site down to crawl it.
Next, we will group using regular expressions. The Rexes show the pattern of URLs of categories in Shopify.
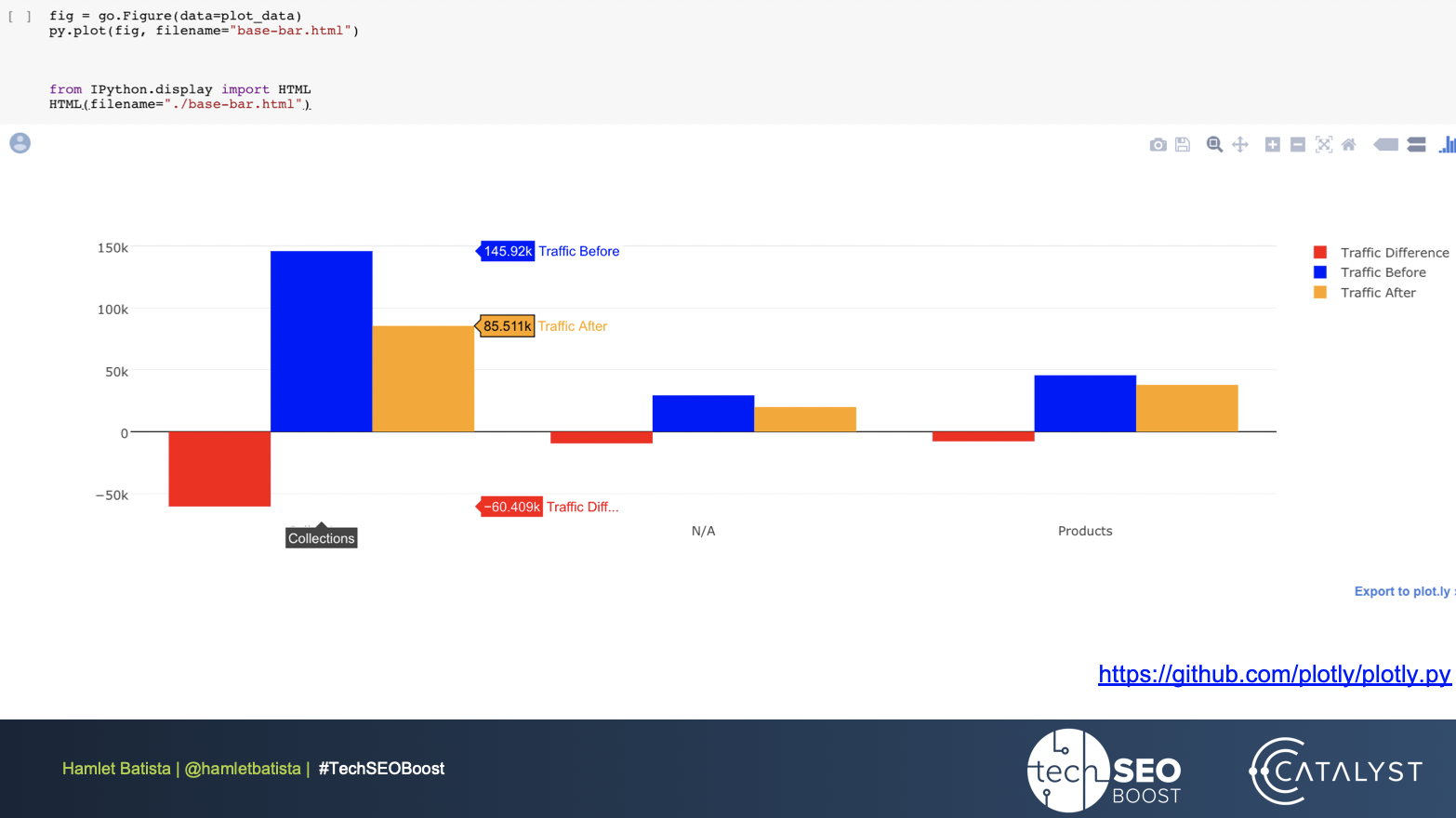
Here’s the beautiful output, where we can see that the collections were the most significant loss for the site. Despite being a lot of work, the results prove to be worth it.
Note that this Winners vs. Losers analysis can also be used when you hit a home run with a client. Sometimes you may not know exactly what you did to enable such great success, so this may help you to understand better and pinpoint the exact solution.
Solution Part 3
Since Regex is primarily useful for pages that have patterns and smaller sites, machine learning can prove to be more useful when handling more data. Instead of matching page groups with Regex, we will match them automatically with the help of BeautifulSoup and Scikit-learn.
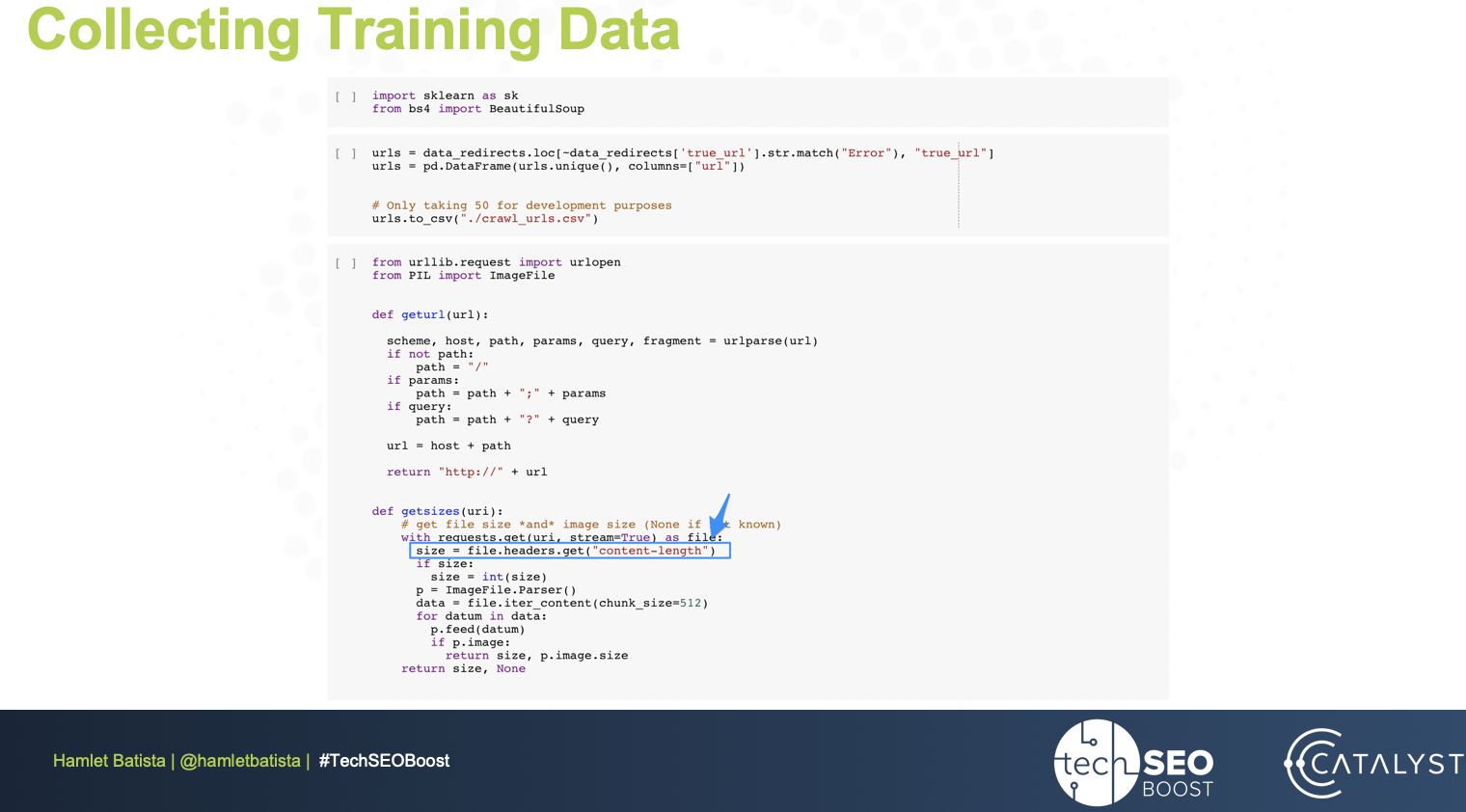
First, we’ll collect training data. A bottoms up approach, used by engineers to solve problems, involves analyzing class IDs, HTML tags, etc. to find patterns in the data.
However, for someone who isn’t an engineer, there is a simpler solution.
In our exercise, Hamlet observes that product pages have big images, while product detail pages have smaller images, but more of them, which he decides to use as his training dataset.
Using this simple idea, he builds an easily verifiable model. Trying to get dimensions of images in HTML may not be accurate, so he approximated by looking at the size of the image (width * length).
When we create the images, we corral them into 50 different categories by using bins.
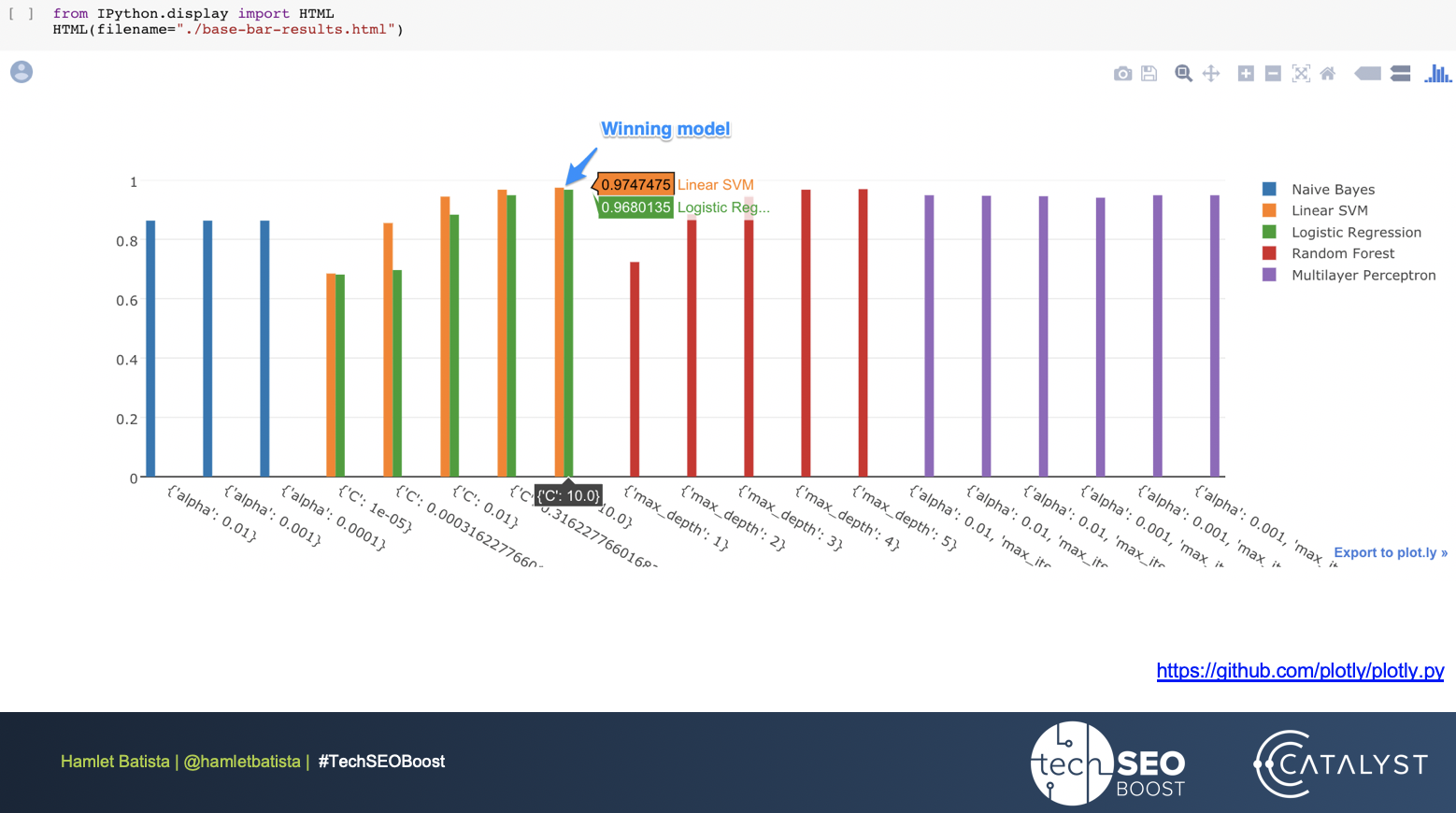
That’s the hardest part: organizing the data in the right way, but the machine learning is really only the one line of code at the end.
Then, we use a grid search with standard parameters to find the best fit model.
But wait… We can do better with Deep Learning!
Solution Part 4
In this phase, we’ll be able to learn what caused the problem more granularly on the page.
Although deep learning is typically used with natural language processing, you can use computer vision as well.
This phase can be done automatically using the concept of the Information Bottleneck Theory, which highlights the difference between data in a 3-dimensional and compressed format.
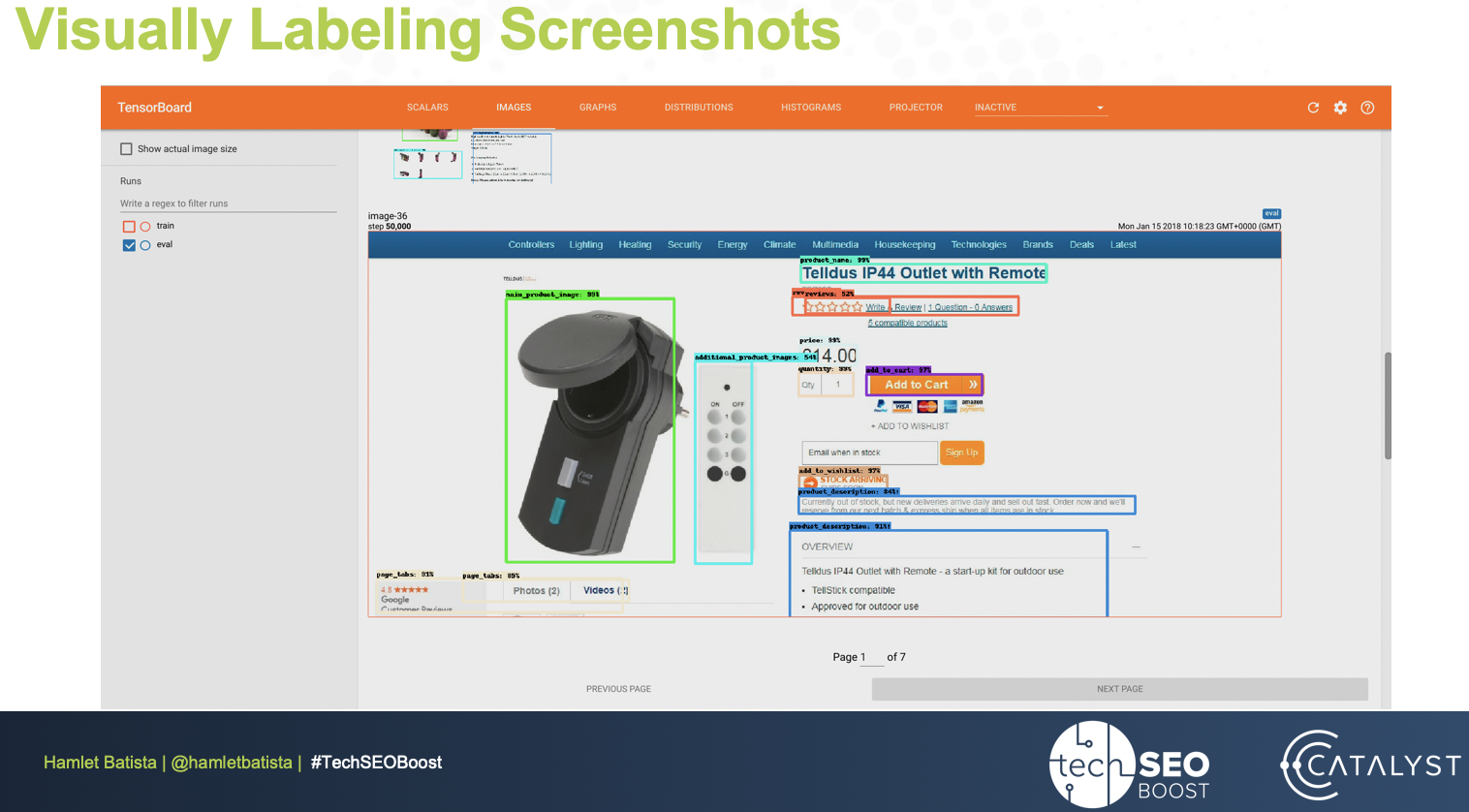
In the compressed format, the computer can clearly dissect elements, learn the classifications of the data, and store it to analyze which pages are performing poorly.
The steps include labeling a few thousand web screenshots with the visual features you find essential, training a computer vision model to predict more granular page groups, and finding the best model.
Programming can be useful to solve interesting problems—consider these tips to help you get started:
Custom Python scripts are much more customizable than Excel spreadsheets. This is good news for SEOs — this can lead to optimization opportunities and low-hanging fruit. One way you can use Python to uncover these opportunities is by pairing it with natural language processing. This way, you can match how your audience searches with your...
As we continue to improve the RankSense app for Cloudflare, we are always working to make the app more intuitive and easy to use. I'm pleased to share that we have made significant changes to our SEO rules interface in the settings tab of our app. It is now easier to publish multiple rules sheets and to see which changes have not yet been published to production.
For the following Ranksense Webinar, we were joined by Antoine Eripret, who works at Liligo as an SEO lead. Liligo.com is a travel search engine which instantly searches all available flight, bus and train prices on an exhaustive number of travel sites such as online travel agencies, major and low-cost airlines and tour-operators. In this...