A recent report published by Moz’s Peter Meyers asked the telling question, “How Low Can #1 Go?”
Organic blue links have continued to be pushed further and further down the SERP. In the article above, a search for “lollipops” displayed the following result.
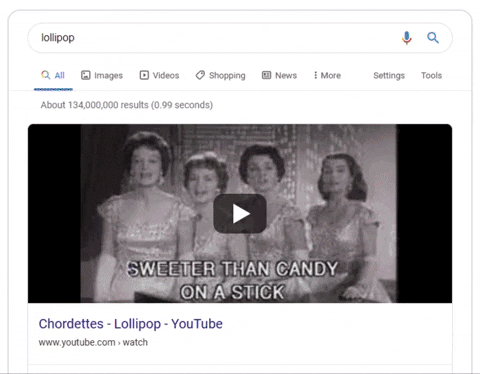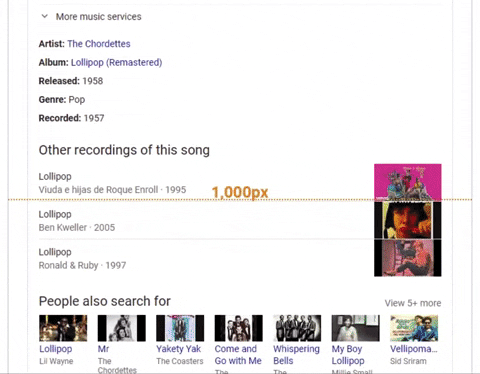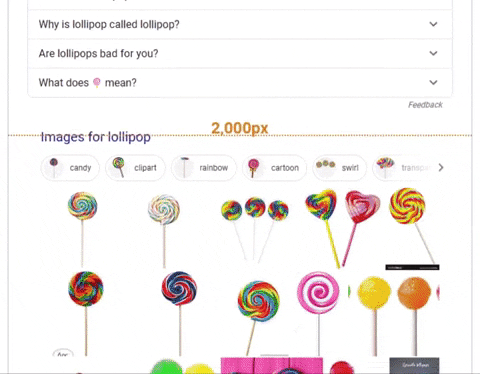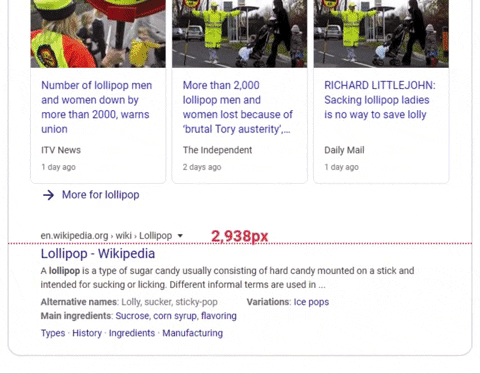
Looks like bad news for SEOs.
But let’s look at the glass half full rather than half empty.
Danny Sullivan from Google challenges this assumption that the ten blue links are the organic listings. In reality, the features replacing them are also organic listings.
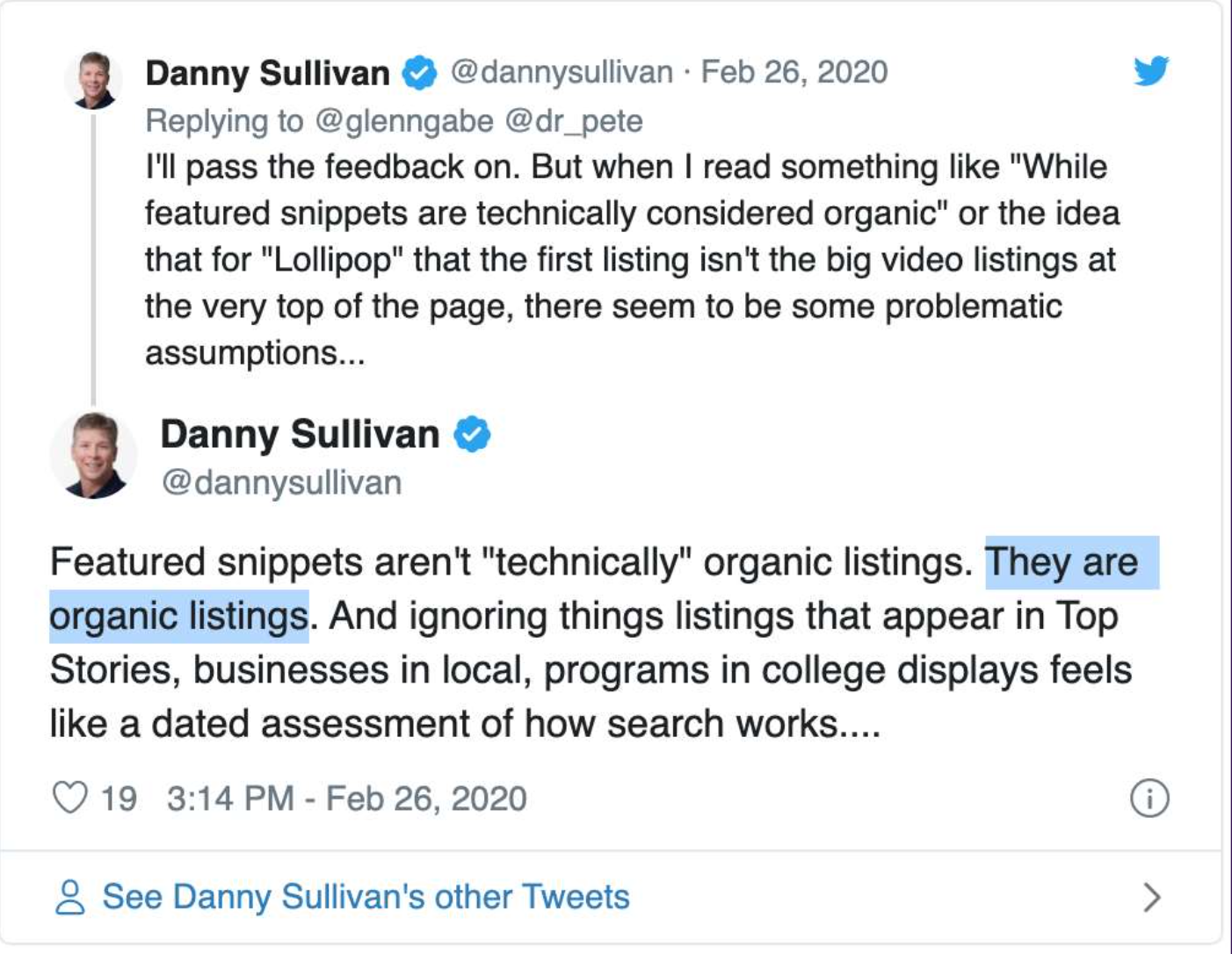
Out with the old and in with the new
When we look back to 2013, keyword research relied on three main steps—researching keywords/topics, building content-rich web pages to match them, and tracking their rankings.

Fast forward to 2020, keyword research has taken a complete 180. According to Moz, a SERP feature can be defined as, “any result on a Google Search Engine Results Page (SERP) that is not a traditional organic result.”
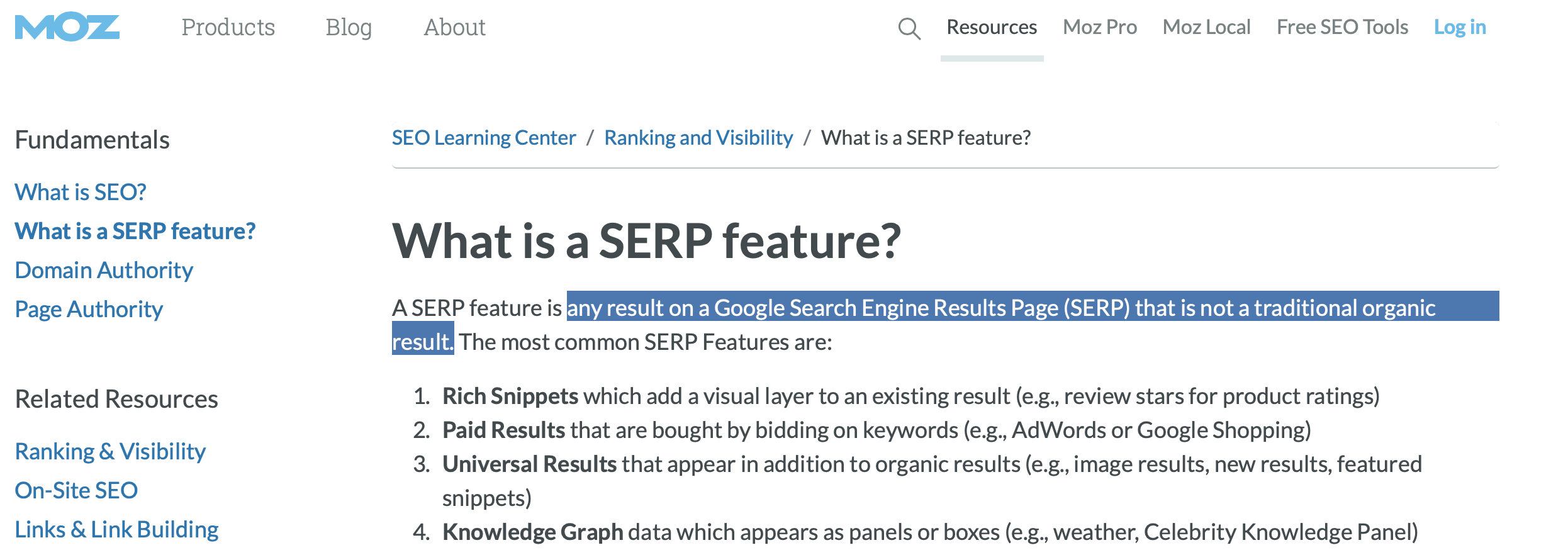
Users’ expectations from Google have changed over time and Google has, in turn, adapted to them through the implementation of these features. For SEOs, the focus should no longer be on how to become the first blue link, but instead on the features that are replacing them.
We’ll use this opportunity as our backbone to scale keyword research to find content gaps.
Here’s what you’ll learn
- Content formats 101
- Mapping content formats to SERP features
- Using SERP features to research content format gaps
- Automating the process with Python
Content formats
Different sites use different types of templates such as articles, forum posts, product pages, tools/calculators, directory listings, etc. These templates serve a specific content need of a user.
- Publisher: articles, archives
- E-commerce: product pages
Among these templates, you can find a variety of content formats such as videos, images, lists, tables, answers, reviews, etc. These more granular forms of content serve as a presentation vehicle for the information.
Instead of filling your content gaps by building content focused on a specific keyword, it’s more beneficial to focus on the content need of the keyword. You can then produce it in a format that will be useful to the target user.
Here’s an example.
In a search for, “how to make a mask,” the first result is a featured video. This specific search calls for a specific content format, a video, which is most useful to the user. Without this type of content, you’re missing the opportunity to be featured.
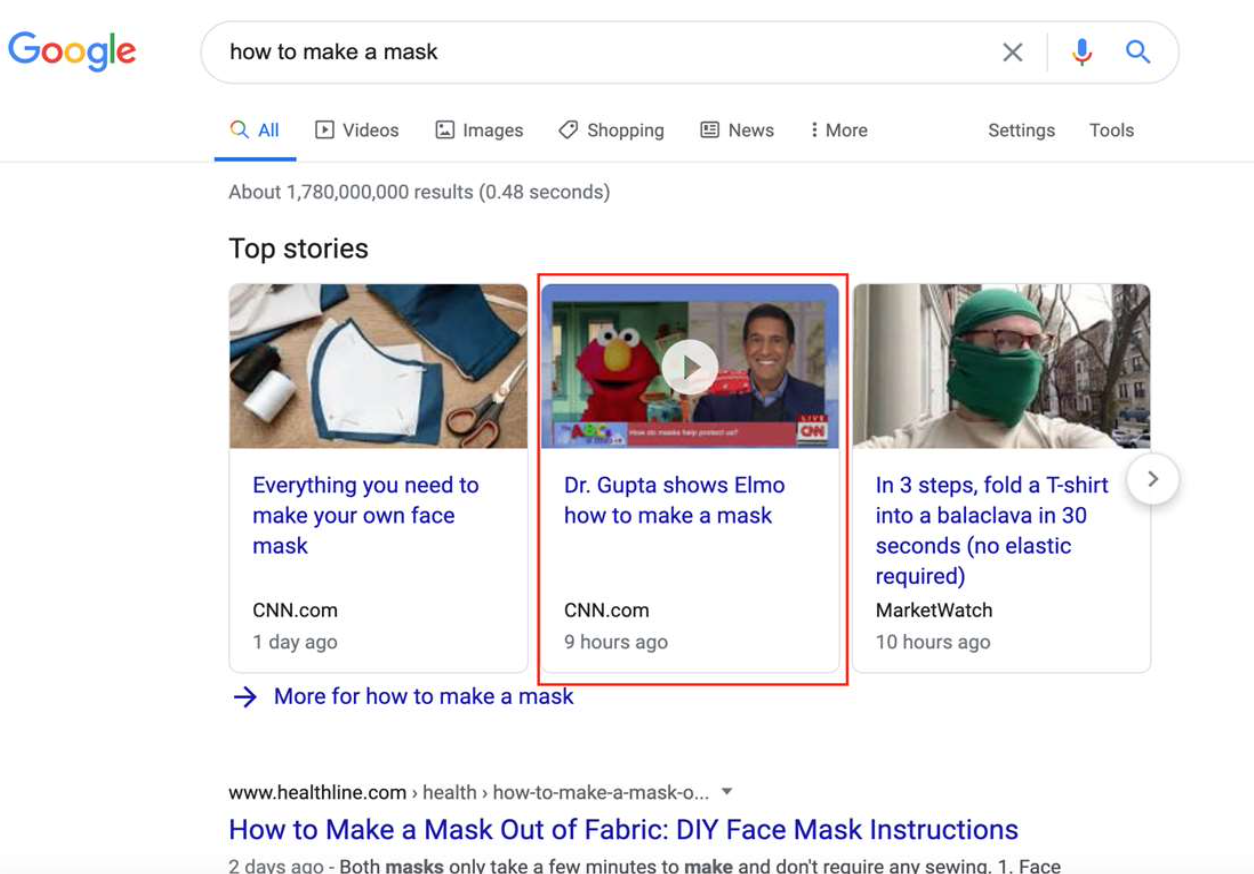
By focusing on the content need of the search you can capture a #1 spot on the SERP without even having to worry about building links to the content.
Detecting content formats in web pages
To find missed content format opportunities we can leverage structured data.
If there is relevant content but no structured data, there is an opportunity to add it.
- Does the page have images, videos, reviews?
If there is structured data but no relevant content, there is an opportunity to add it.
- Is there a specific information need we can fill?
Here’s an example using Google’s Structured Data Testing Tool. When we run this URL, we can see there is an image and a video embedded on the page.
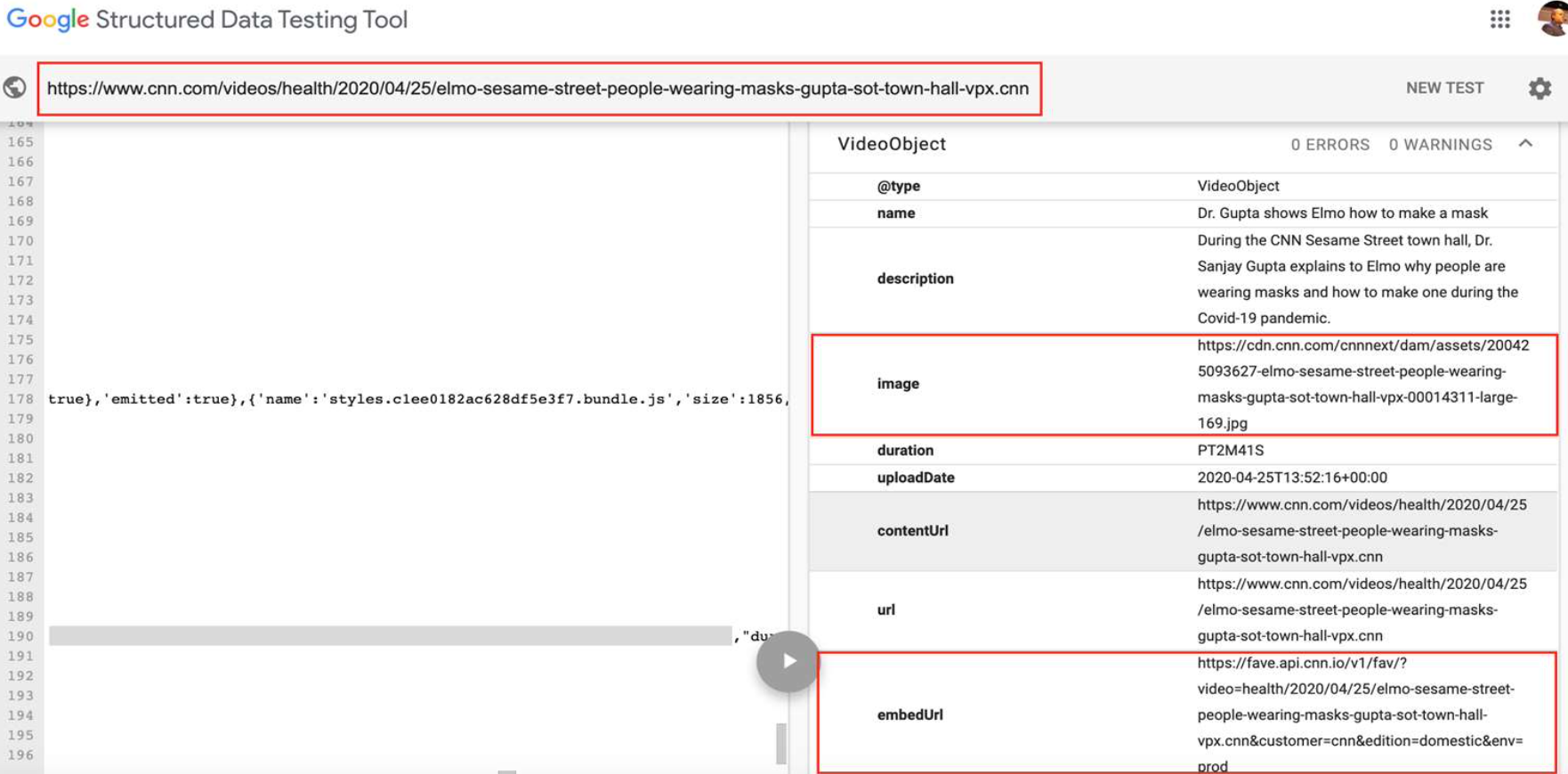
Manually, Hamlet mapped out SEMrush SERP features to a specific content format (reviews, videos, answers, etc.). He also used JSONPath to identify within the structured data whether the expected content was on the page.
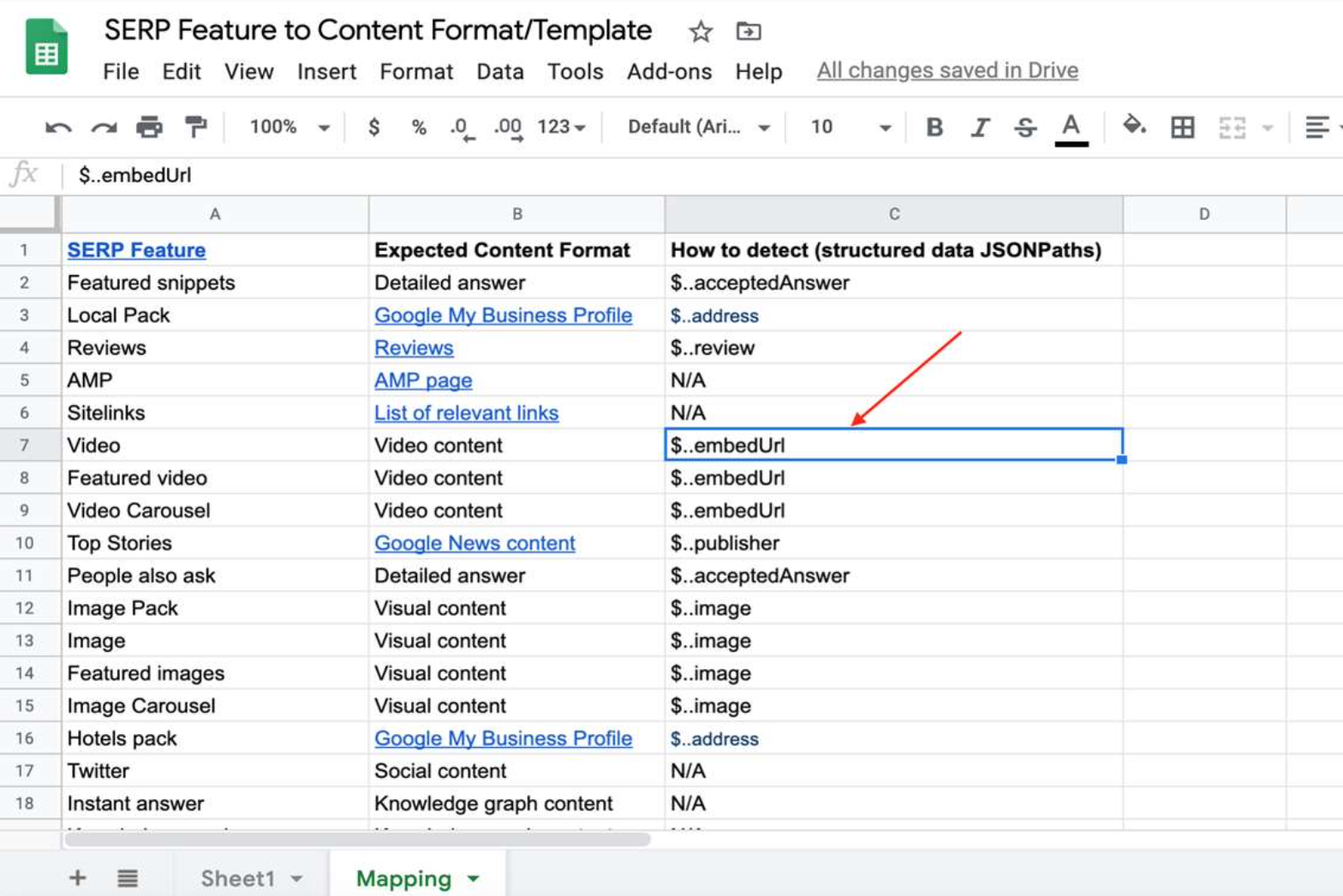
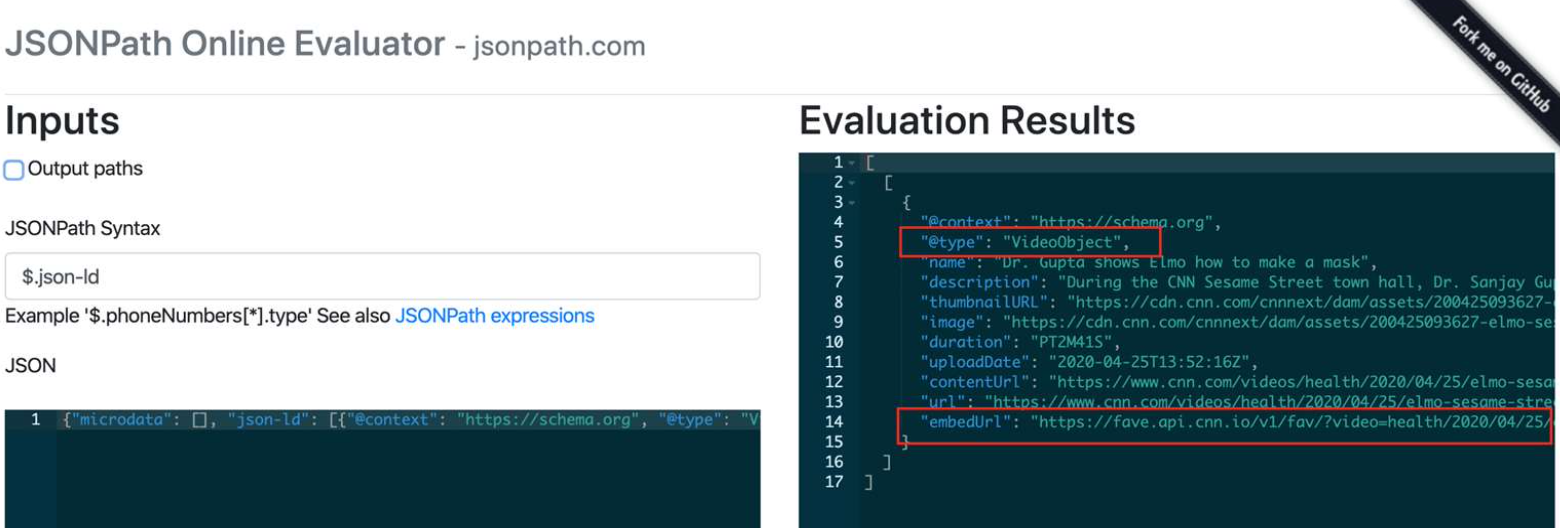
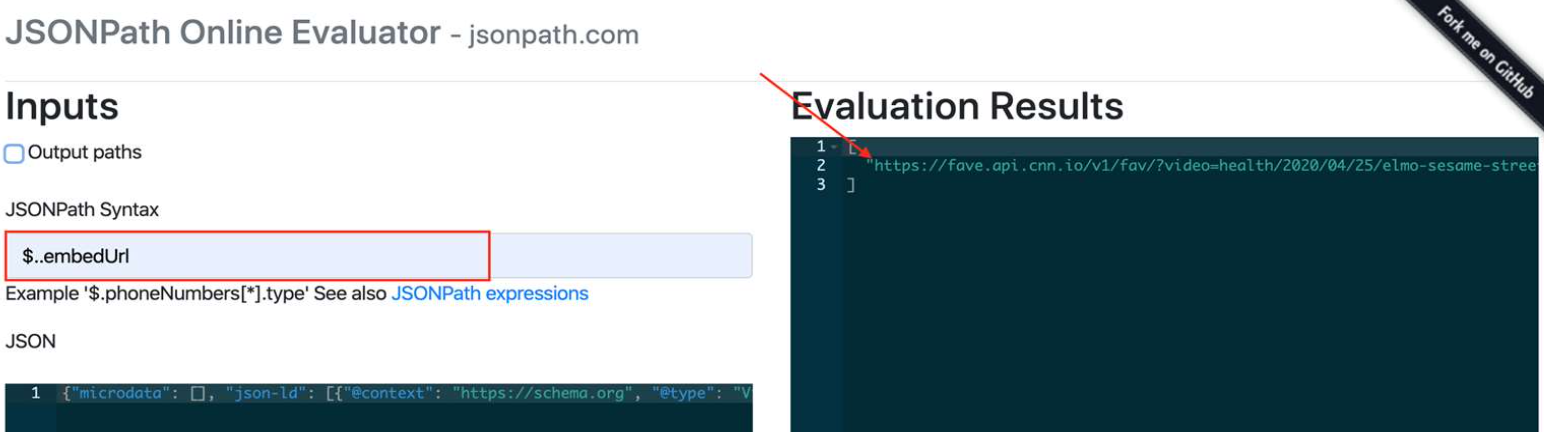
JSONPath is similar to XPath or CSS selectors, but it is for JSON output, typically used to extract structured data. In this example, he uses the selector for the video from the previous URL to determine whether the page has that specific content format.
Let’s automate this!
Now that we know the opportunity and the building blocks to realize it, we will follow this technical plan to determine content gaps:
- Extract keywords (and pages) with high impressions and no clicks
- Extract SERP features for those keywords
- Use our Feature->Format (JSONPaths) map to identify content format expected
- Check if a page includes a target format
- Report content formats missing
Extracting underperforming keywords and pages Google Search Console
To extract keywords with high impressions and no clicks we will use the code from Hamlet’s previous webinar with Traffic Think Tank.
First, clone and install the library from the search console.
- !pip install https://github.com/joshcarty/google-searchconsole
Next, configure the Search Console API.
- Activate Search Console API in Compute Engine (use $300 credit)
- Create new credentials / help me choose (Search Console API, Other UI, User data)
After this download, you can upload it with this code to a new Colab notebook. Run it once and it will prompt you with a URL allowing you to authorize our Python code to access the Search Console data.
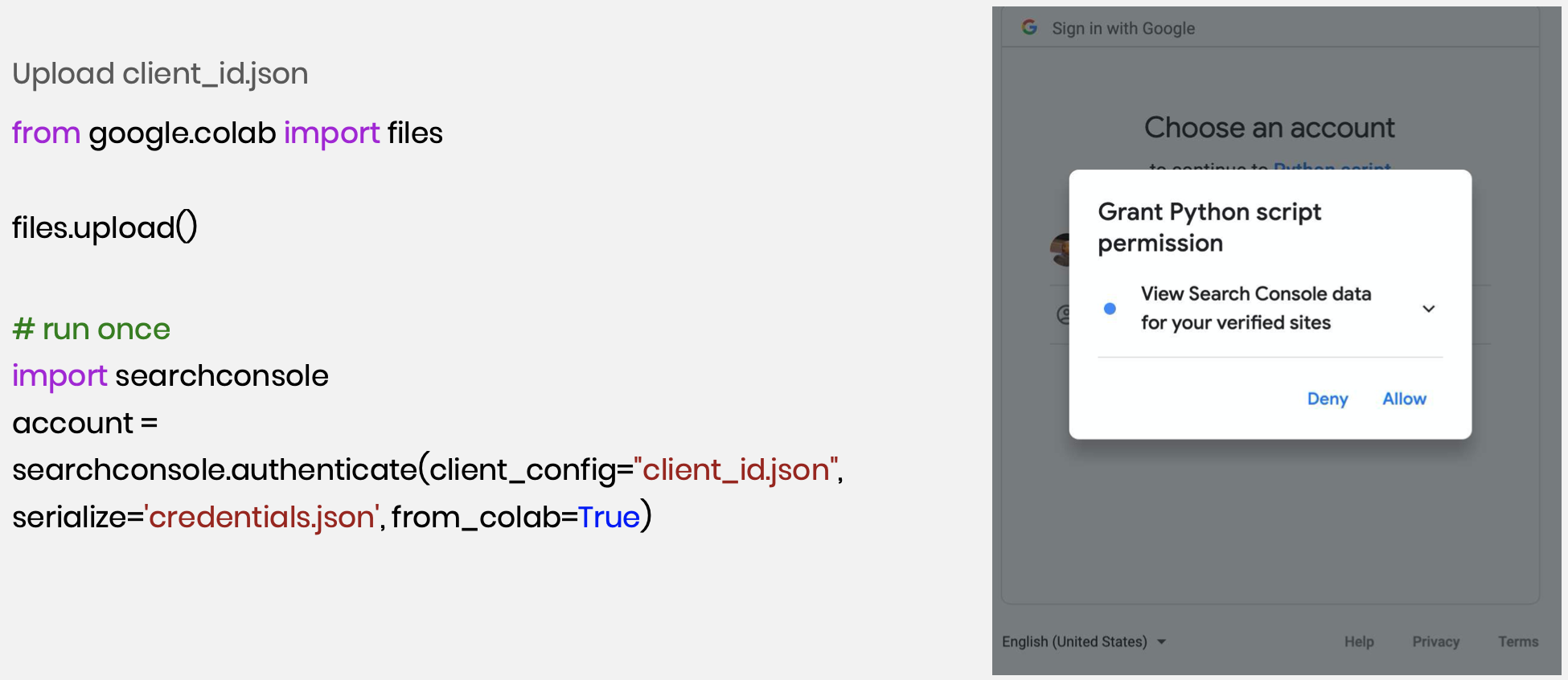
With these few lines of code, you can pull as much data as you want. Here we pulled 7 days of GSC data and built a data frame in Pandas.

Here’s the result. Although you can get something similar in Search Console, you can’t get keywords and pages in the same dataset. With these simple few lines of code, you can achieve this.

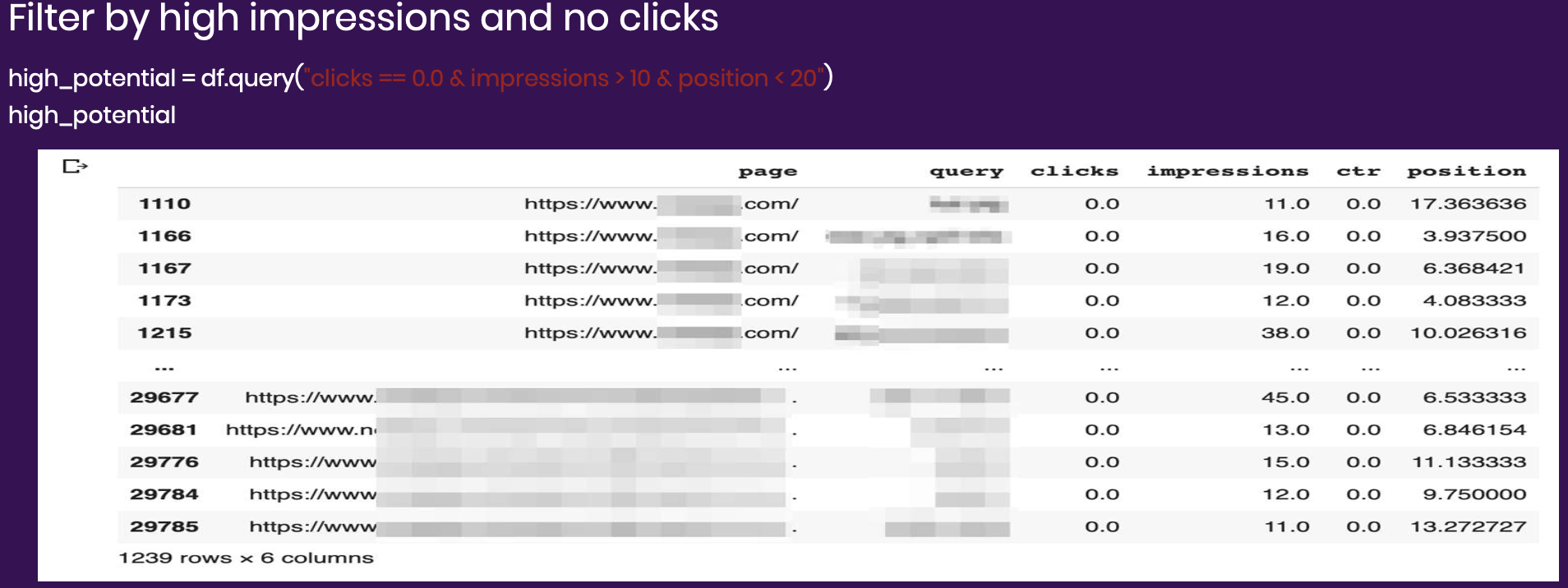
Now we can filter it so that it shows which keywords have zero clicks, at least 10 impressions, and rank under 20. This is the opportunity—keywords that rank well and get enough searches but aren’t getting any clicks.
Extracting SERP features from SEMrush
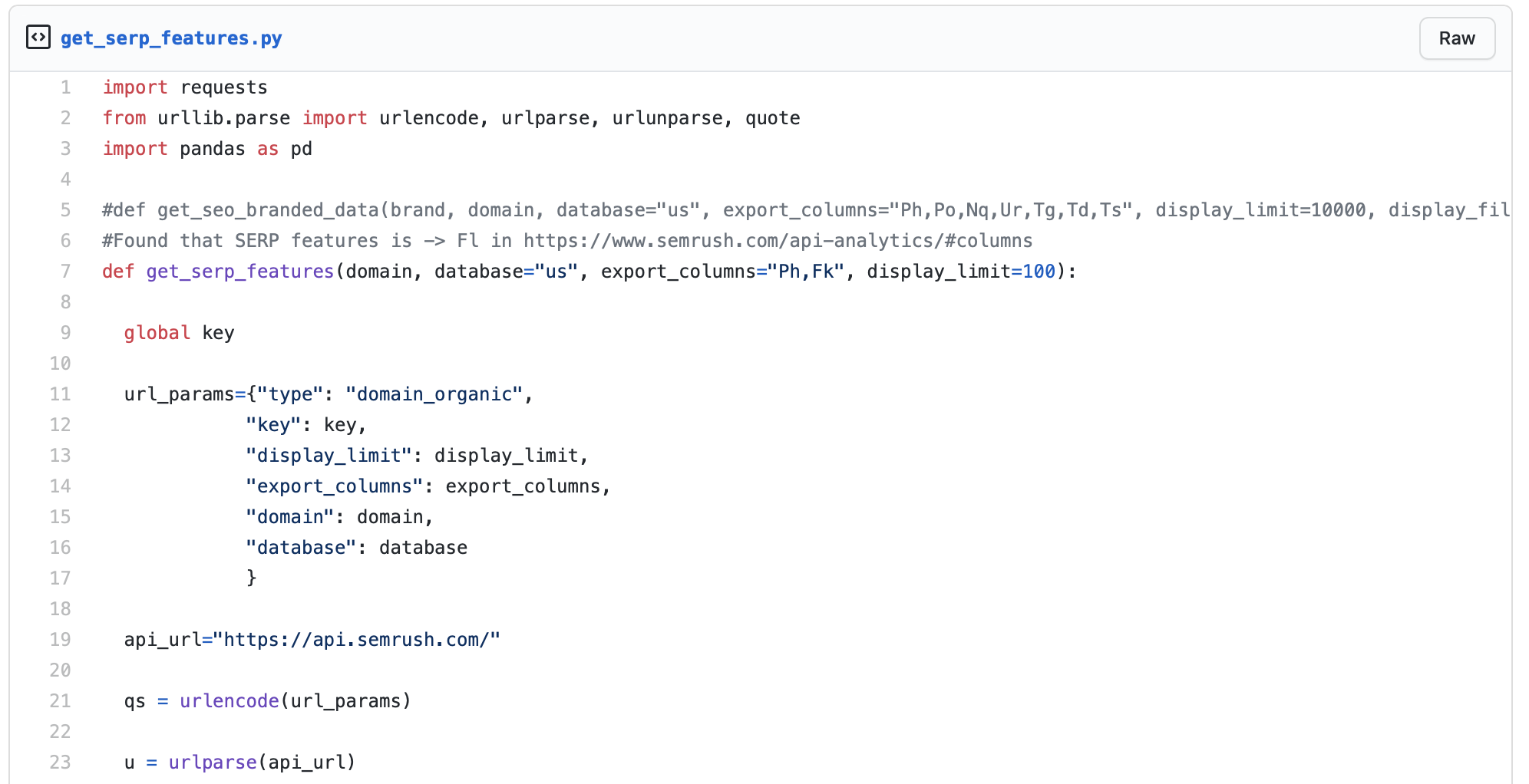
Now that we have these keywords from Search Console, we will pull SERP features from SEMrush. The code we will be using is from a previous webinar Hamlet did with them. You can start by finding the SEMrush API reference here and your API key here. We’ll be using two features:
- Fk: all SERP features triggered by a keyword; list of available SERP features
- Ph: keyword bringing users to the site via Google’s top 20 organic search results
The code, found in this Gist, will essentially pull the SERP features for keywords in SEMrush using the same domain we used in Search Console. In addition, here is another Gist that has a function to pull the incidences used for the features and translate it into their actual names.
When features are pulled initially, they include these numbers which don’t mean much, however, they will be mapped into their names. This line of code will display SERP features by keyword.

Now that we have the underperforming keywords from Search Console and the SERP features for these keywords from SEMrush, we can merge the two datasets by intersecting the keywords they have in common. The code below will join the query and keyword columns.
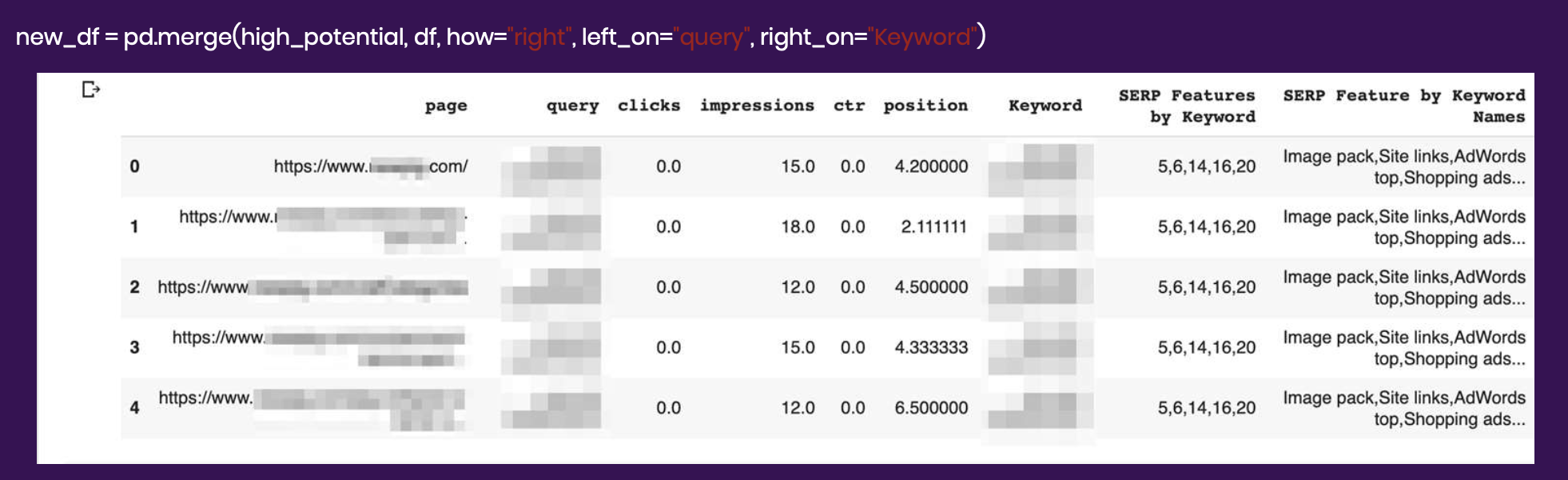
This is important because the SERP features show what type of content is in high demand for each keyword. For the prior face mask example, if you are missing a video format for that keyword, you are missing an opportunity. You can capture a top story simply by filling in a content format gap.
Checking if pages include expected content formats
To check if pages include their expected content formats, we will be using the following libraries:
- Requests
- Extruct — a python library that allows you to fetch structured data from a page
- Jsonpath-ng
Using this, we will extract all structured data from the page and map the expected formats to JSONPaths.
!pip install extruct==0.7.32.
!pip install rdflib==4.2.2
Here is an example. Using very simple requests to the page and the CNN URL from earlier, we use a call to get the base_url from the response. It will then extract all the structured data.

This is the output. The JSON-LD has all the structured data for the page. It shows us the video URL, image, and thumbnail. We can also see that there is no microdata or microformats, but there is open graph meta data. Most of these are features are supported and used by Google and other search engines.
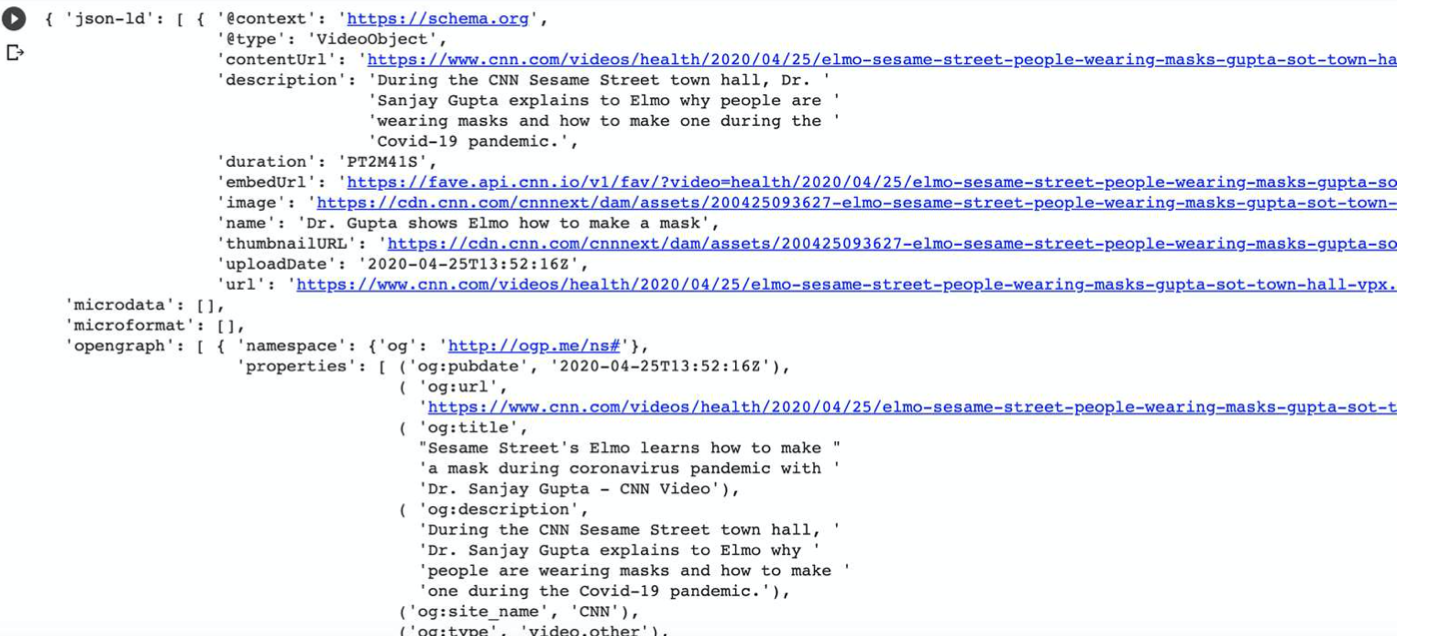
Very easily from python and without having to run the structured data testing tool, we can pull the structured data from the page in an easy-to-use format.
Now that we have this structured data, we are going to test the JSONPaths to extract specific elements from each type of structured data to learn whether it includes what we’re expecting.
If we’re looking for:
- Questions, we’re looking for the element $..acceptedAnswer
- A local business listing, we’re looking for the element $..address
- A product review, we’re looking for the element $..embedUrl
This fetch of a required element will show if it is on the page or not.
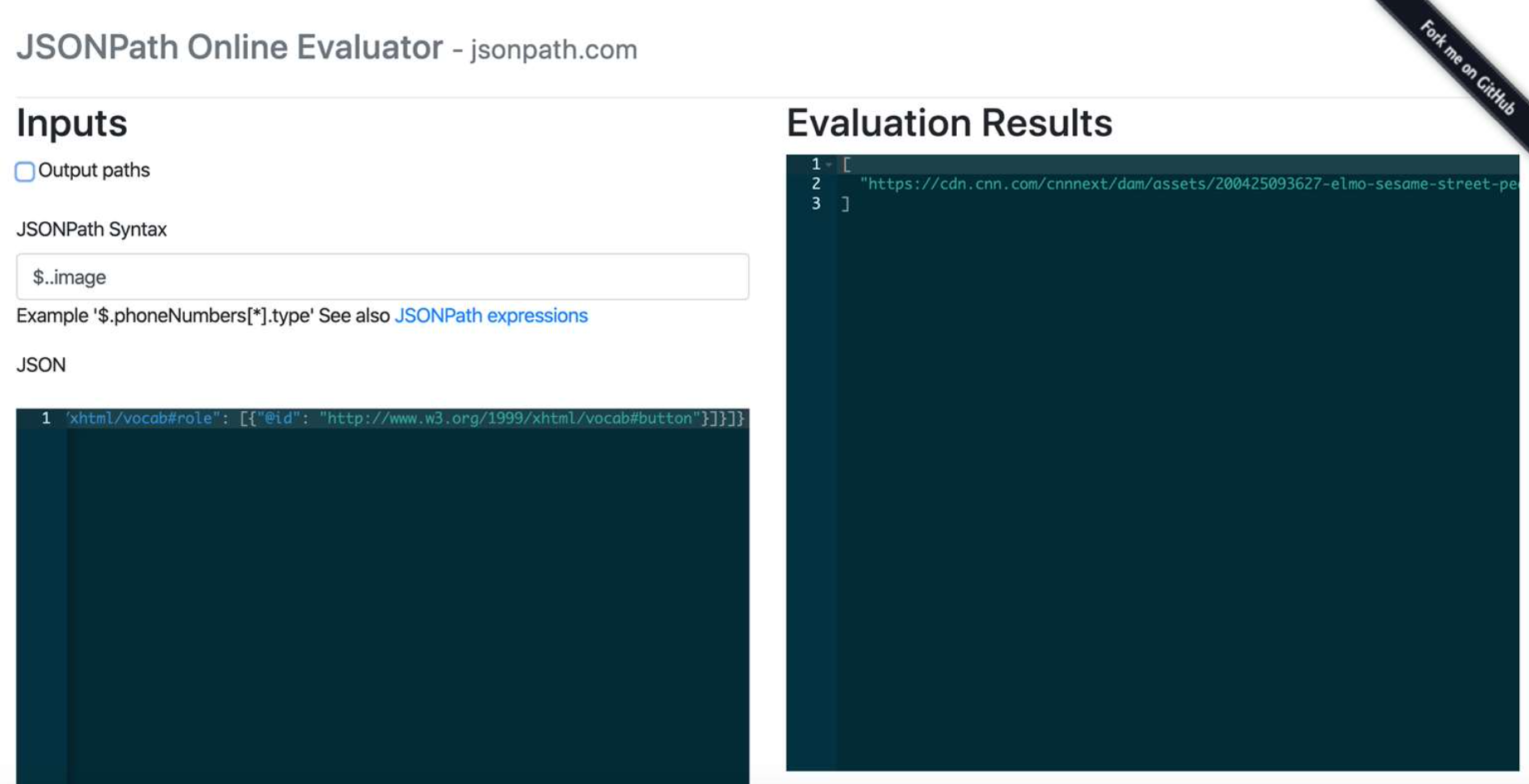
Take the example of a job listing. If we run this code with a job search, we can see if the top-ranking URLs include the $..employmentType element. If they do not, we can take advantage of the opportunity.
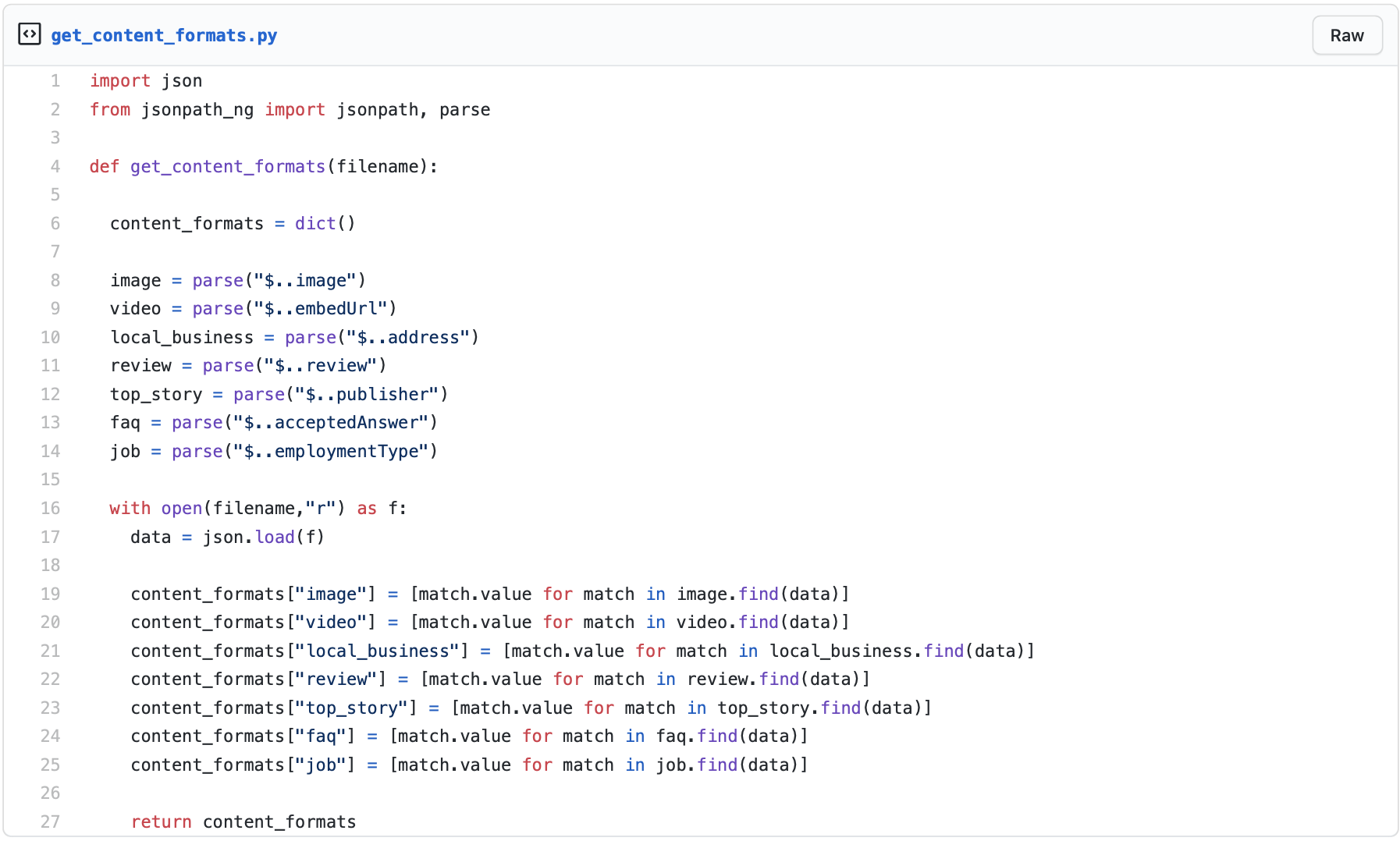
Here is the code for that. In it is a function to check the content formats of a specific page.
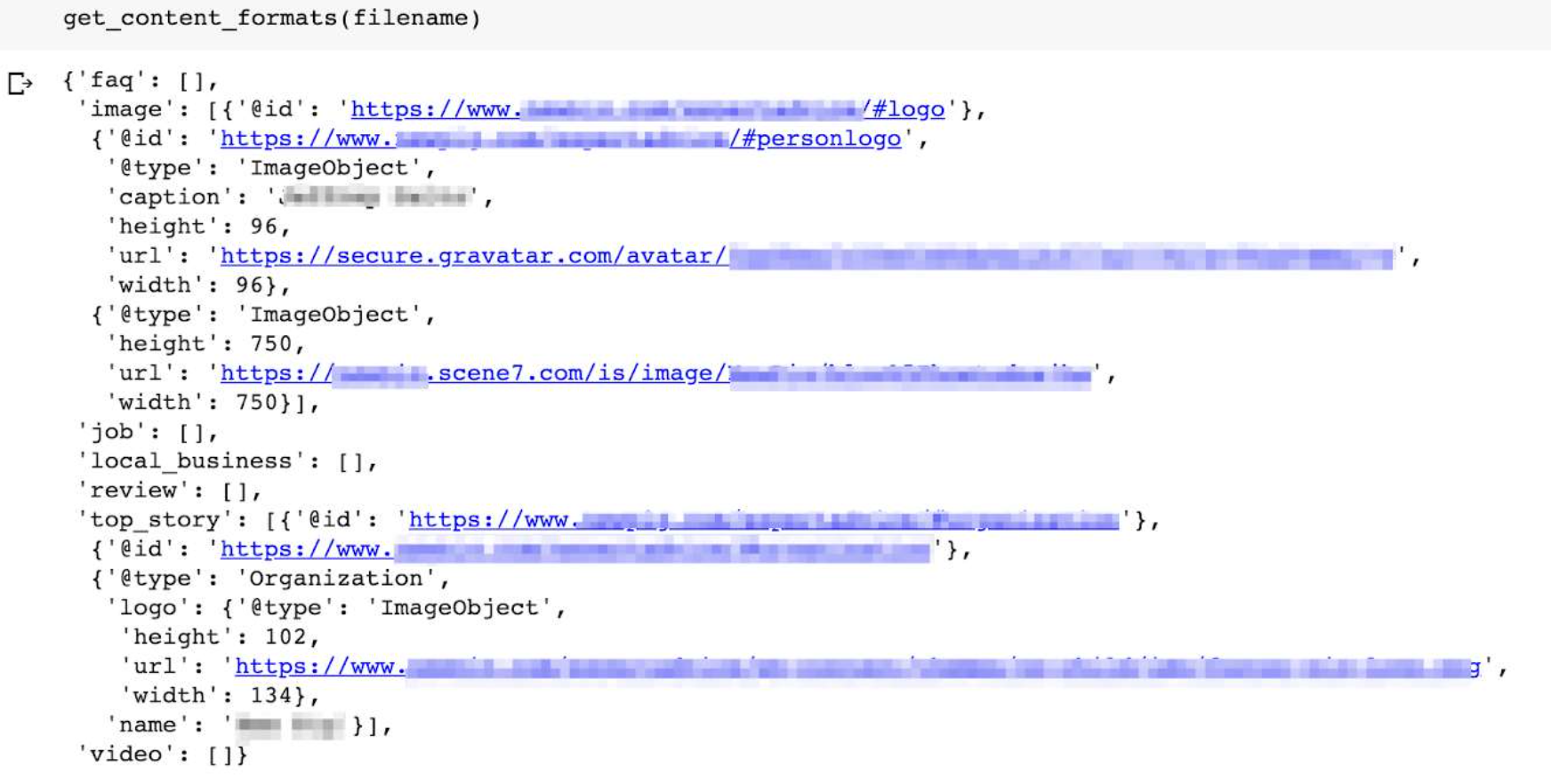
Here is the output. Essentially, we’re checking if the page includes the key things we’re looking for in the structured data, such as, top stories or video, so that we can easily identify which content formats are presented.
All this information can be pulled in an automated way, saving you a lot of time.
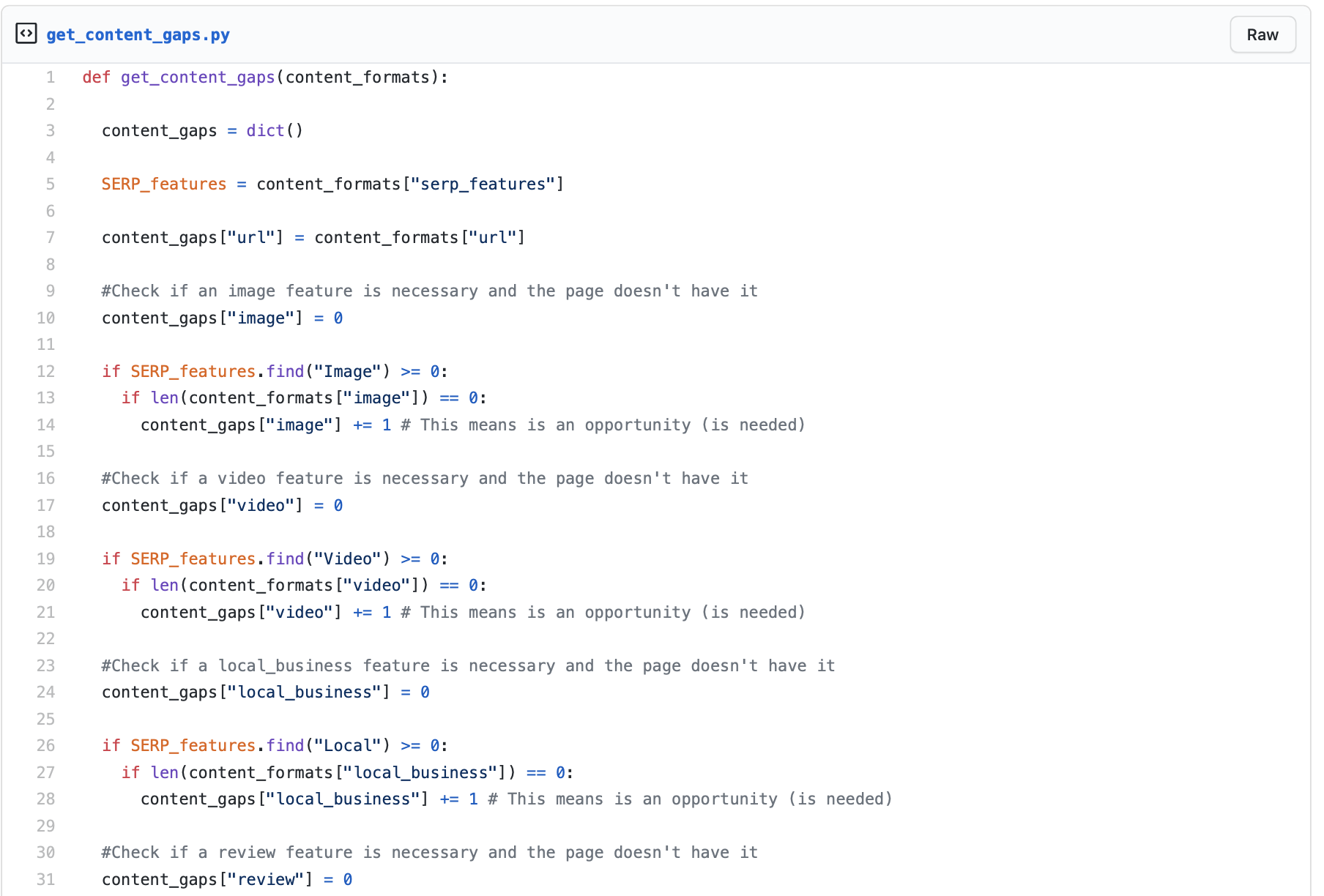
To calculate the opportunity gaps, Hamlet shares this function using the content formats and SERP features. We consider it an opportunity if there is a SERP feature (for example, a video carousel), and there is no corresponding content format on the page (no video in the structured data). We count opportunities as 1.
This is the output. When we run this code, it shows where an opportunity is possible.
Report missing content formats
Although the previous code was useful to show opportunities available, it’s not easy to visualize.
We will create a heatmap to provide a better visual.
The blue-colored areas mean there’s a request for a specific keyword, but the need is met because the page has the desired content format already. The yellow areas show where there is a request, but the desired content format is unavailable. These are the areas of opportunity.

For this client specifically, we can see the biggest gap is in videos, which makes sense since they can be expensive to produce. However, by capitalizing on this demand, you can make a worthwhile investment.
Here’s the code to get this output.
First, we’ll be using a library called plot.ly. We will then specify the columns, “image”, “video”, “local_business”, etc. and create a heatmap.


View Hamlet’s slide deck from this presentation:
https://www.slideshare.net/hamletbatista/scaling-keyword-research-to-find-content-gaps?qid=1b9da2e1-01d8-49dc-bdbb-3ed4d9ead965&v=&b=&from_search=1
Resources to learn more
An Introduction to Python for SEO Pros Using Spreadsheets
Search-Driven Content Strategy
Query Syntax
SEO Automation Course
