Table of Contents
- Introduction
- Crawler traps created by faceted navigation
- Fixing crawler traps through the implementation of robots.txt directives
- Manually checking the faceted navigation
- Using the RankSense app to identify and fix crawler traps
Introduction
It is crucial for SEO that every website gets crawled by a search engine’s web crawler, such as Google’s Googlebot. These crawlers index the web pages on your website to later serve them up on their search results pages. Due to their significance, it is essential to make sure they are crawling your site efficiently.
The crawl budget determines how many pages the crawler would get to on any given day. The budget can have some minor fluctuations, but overall stays relatively consistent. This concept is not as relevant to small websites (a few hundred pages) as a full crawl for the entire site can happen relatively quickly. However, for major websites (typically in e-commerce) consisting of over tens of thousands of pages or more, it is essential to verify that there are no crawler traps or infinite crawl spaces present on the site.
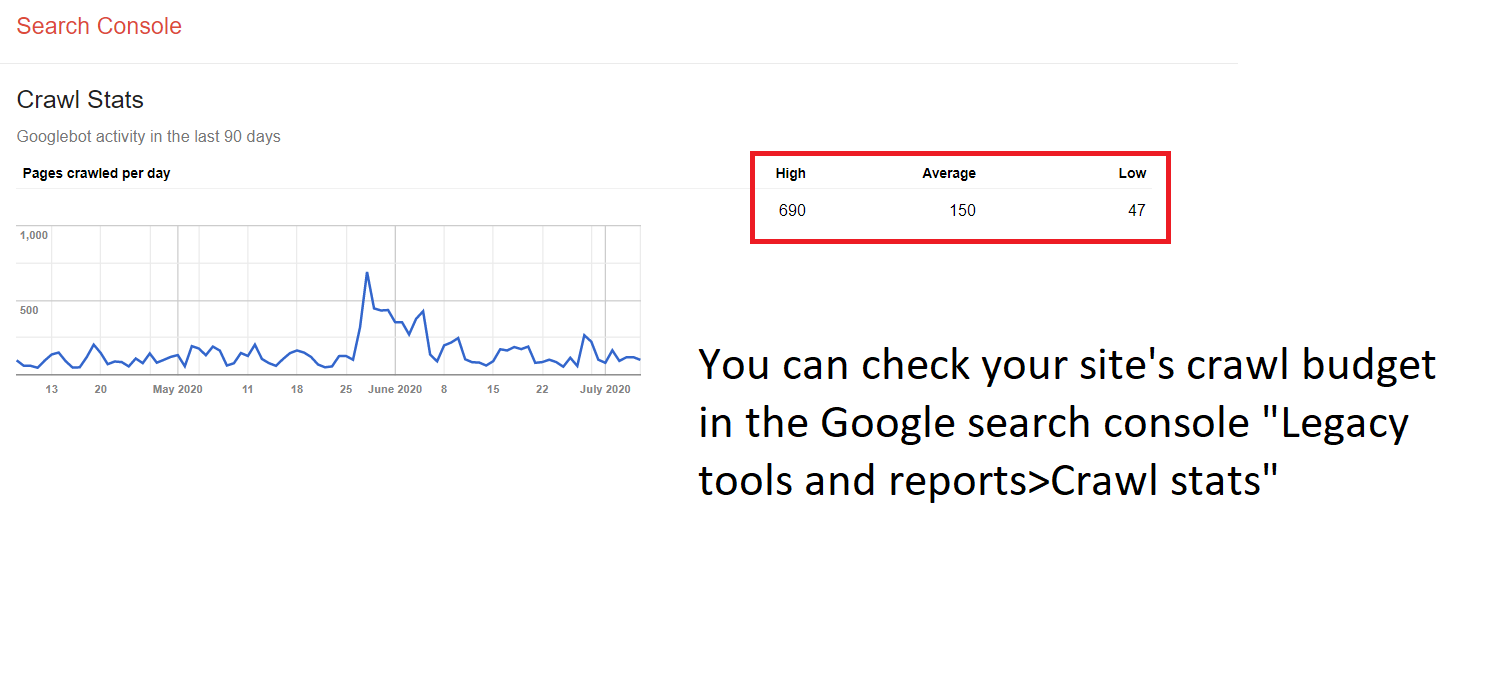
Using the RankSense Cloudflare app and an SEO crawler such as SiteBulb, you can locate crawler traps, implement fixes to improve SEO results, and monitor the performance of your changes to evaluate their success.
Crawler traps caused by faceted navigation
Most, if not all, e-commerce websites use some form of faceted navigation: a simplified UX technique allowing users to find the exact product they are looking for. Any large website using a form of faceted navigation can produce crawler traps, preventing the web crawlers from focusing on the important and unique content on the website.
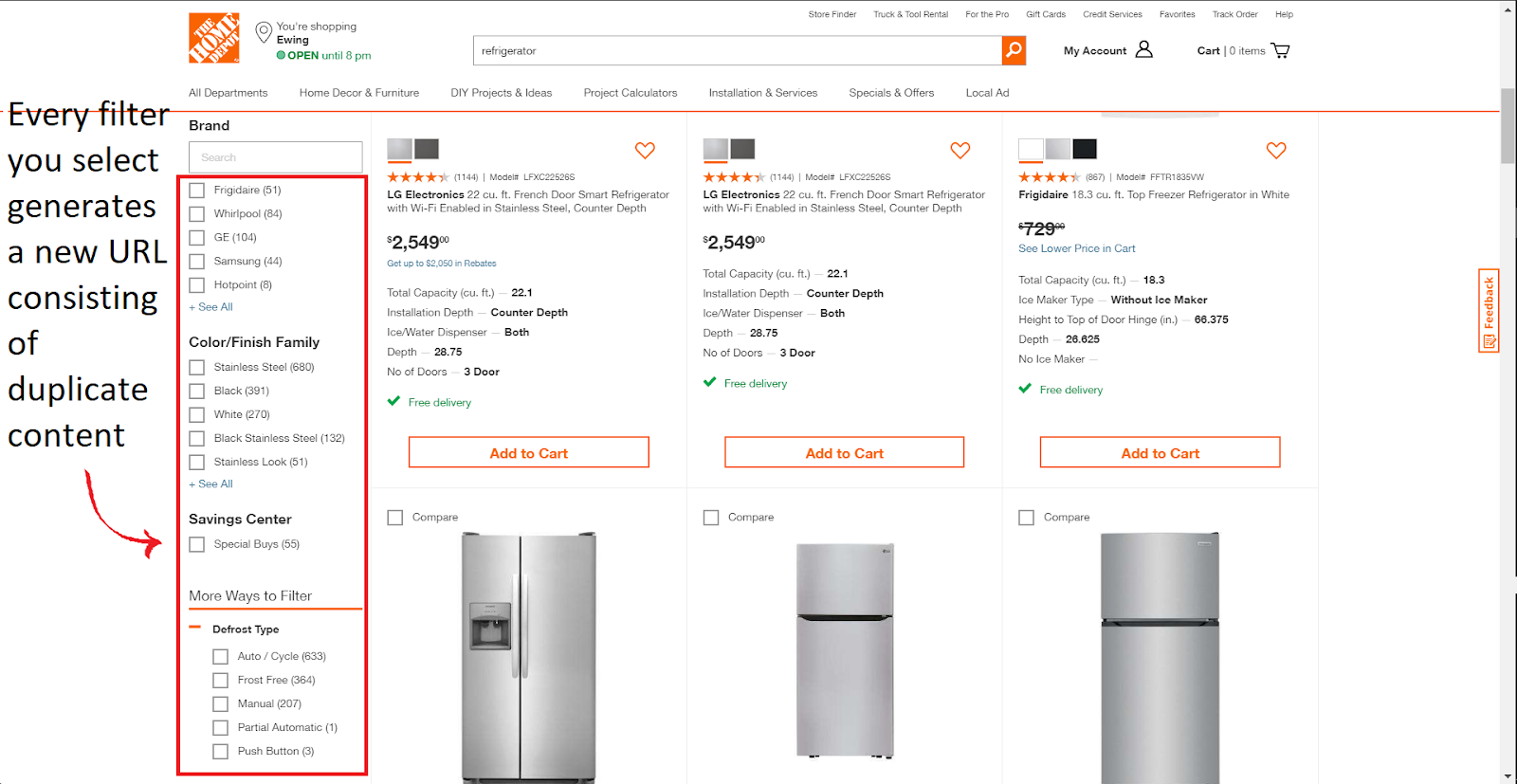
(Example of faceted navigation on homedepot.com)
The problem with faceted navigation is that many times it generates a new URL every time a new filter is selected to display the products matching those specifications. When these websites have thousands of product pages with multiple filters, there could potentially be millions of new URLs generated, all showing the same content found within the base category page. The web crawler could get stuck crawling all of this low quality duplicate content.

- (This is the URL of page 1)

- (This is the URL when I filter for Samsung fridges)

- (This is the URL when I filter for stainless steel and white Samsung fridges)
This can go on and on as there are over twenty filters.
Typically, most duplicate URLs that could lead to crawler traps or infinite crawl spaces have canonical tags associated with them to let Google know to canonicalize the URLs accordingly. For Google to properly recognize and process canonicals though, it must first index those pages.
Though this may not be an issue for smaller sites, for big sites with tens of thousands to millions of pages, this “processing” step could potentially take a long time, and Google will continue to crawl a large amount of “low quality” pages for a while. We have found time and time again that the more efficiently we can get Google to crawl a site, the more successful SEO results we have seen.

Fixing crawler traps through the implementation of robots.txt directives
One solution, which has provided fantastic results in the past, is the implementation of robots.txt disallow directives on URL patterns that cover faceted navigation, preventing the web crawler from crawling these almost infinite amount of URLs.
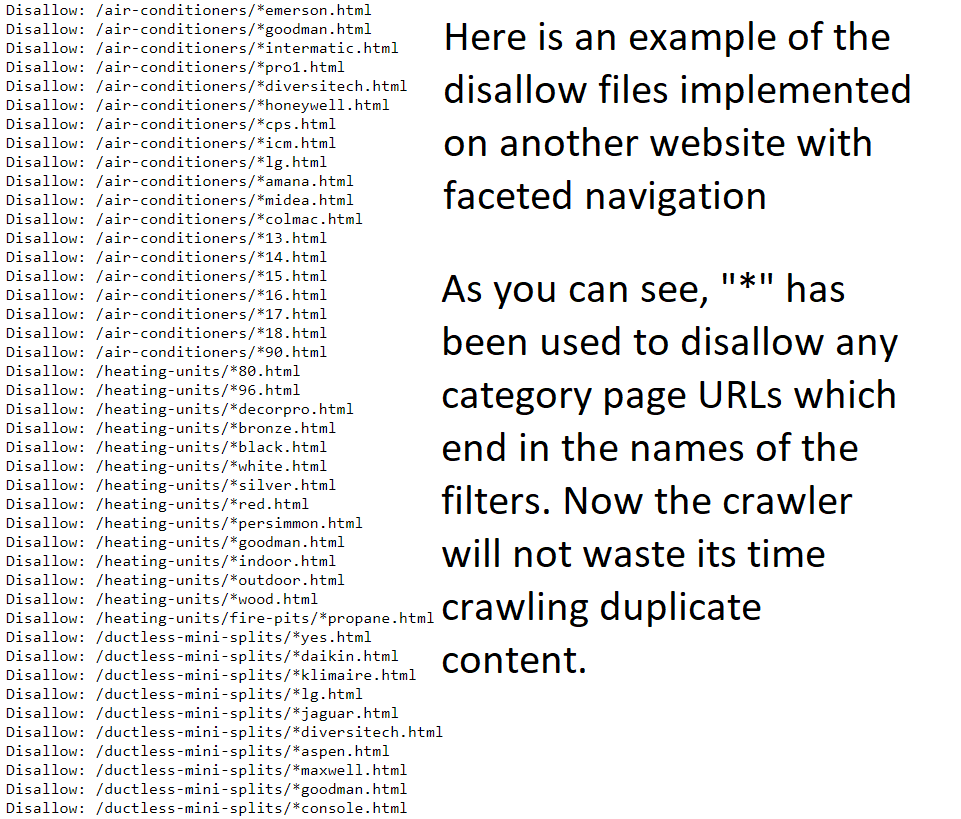
Taking a look at the screenshot, you can identify the multiple filters contained in the faceted navigation (ex: black, white, silver, red). Since each of the URLs following these patterns will display low quality duplicate content, the disallow directives are necessary.
Manually studying the faceted navigation
To get an idea of what kind of duplicate URLs your faceted navigation produces, you can apply the filters and study its effect on the URL. Since the path of the URL changes after each filter is selected, studying these changes will allow you to disallow these paths and make the implementation of the robots.txt directives less tedious.
Although this method is a viable way to fix the issue, it still requires a decent amount of labor and does not guarantee a fix. It is easy to miss some URLs and quite challenging to identify every single occurrence of a potential crawler trap.
For these reasons, it is quite helpful to use the RankSense SEO tool and an SEO crawler such as SiteBulb during the process to identify and fix crawler traps.
Using the Sitebulb SEO auditing tool to identify crawler traps
Step 1: Installation
If this is your first time using Sitebulb, you can download it by heading over to their website: https://sitebulb.com/.
Next, click “Try Sitebulb For Free” and click on the download for your operating system.
Once you install Sitebulb, open the application, and create a free account.
Step 2: Crawling your website
To start crawling your website, you will have to create a new “Project” in Sitebulb. Simply click the green “Start a new Project” button to get started.
Here you will name your project and select a URL to start the crawl. Once you enter these things, click the green “Save and continue” button.
The Audit Setup page is where you can adjust any settings to finetune your crawl. You can simply just click the green “Start Now” button to start the crawl.
Step 3: Identifying crawler traps:
If your website has no disallow directives to avoid crawlers from crawling infinite crawl spaces, you may notice that the “Overall Audit Progress Completion” bar and the “Crawl Progress” bar are stuck. This is due to the crawler discovering thousands of new URLs generated by the faceted navigation.
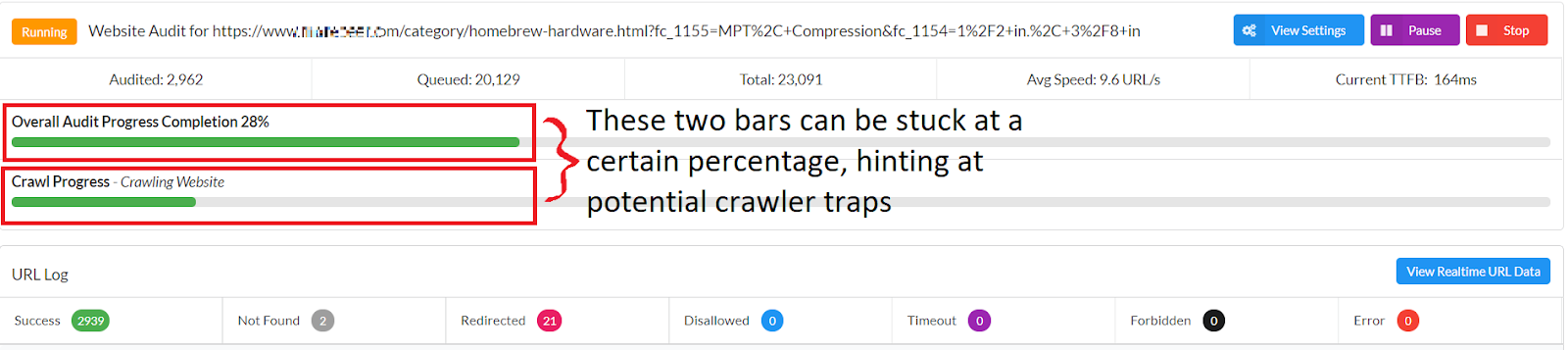
(Note: Just because SiteBulb is not crawling your website super quickly, it does not automatically mean that there are crawler traps)
If you click “View Realtime URL Data,” you can study the URLs that have been discovered by the crawler. Here is an example of what an infinite crawler trap could look like.
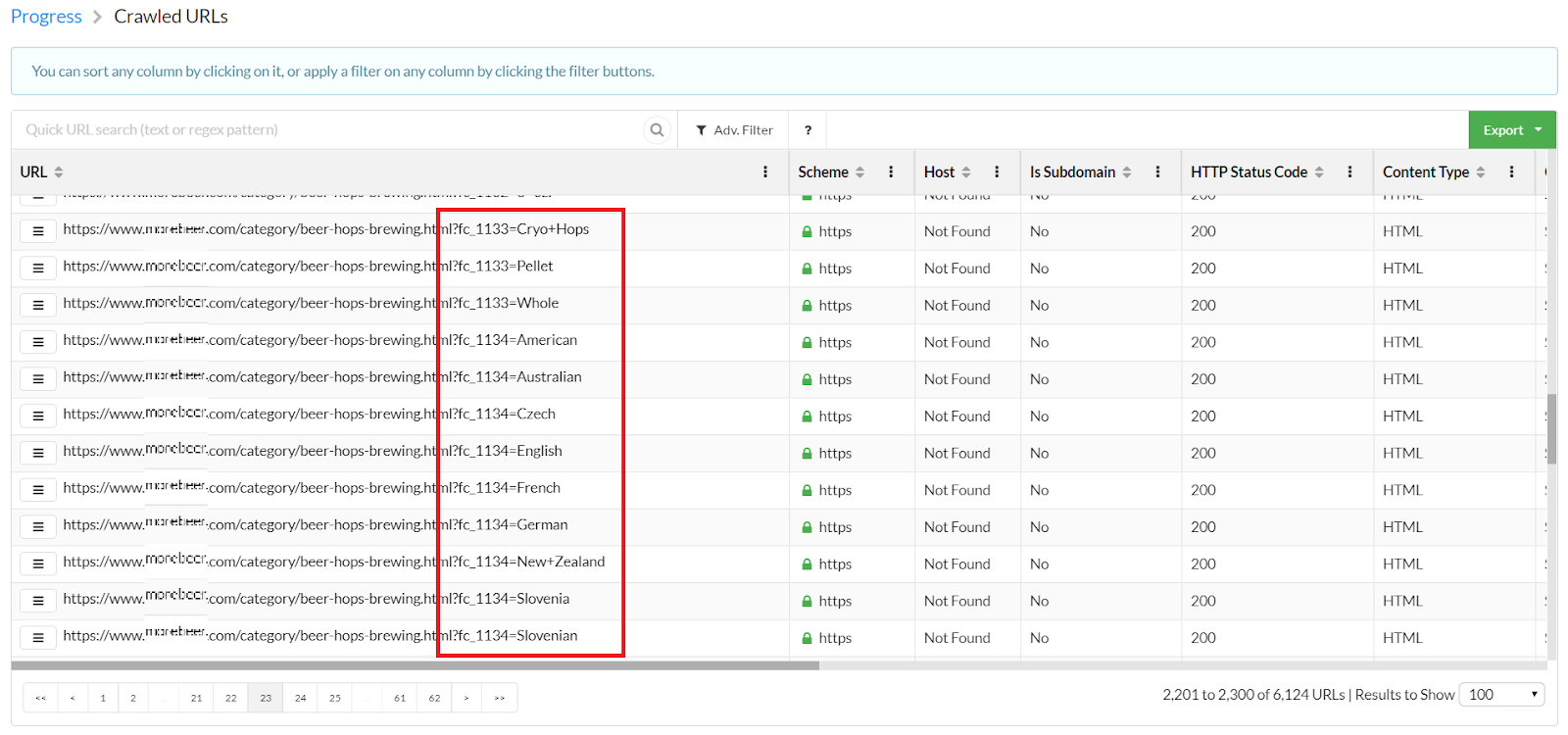
On this particular website, you can filter the beer hops by region. This creates a lot of similar-looking URLs, which all contain low quality duplicate content, resulting in a crawler trap.
As you can see, you can find crawler traps on your page by using a simple web crawler to replicate what Googlebot sees.
(Note: If this is your first time using SiteBulb, feel free to explore the many options it has.)
Implementing your changes using the RankSense SEO tool
Once you have identified the crawler traps on your website, you can start implementing robots.txt disallow directives on those URL patterns. An easy way to add these robots.txt directives is by adding them to a “rule sheet” and uploading them to the RankSense Cloudflare app.
Step 1: Installation and rule sheets
If you do not have RankSense installed, you can do so by following the steps in this article. If you are not familiar with creating custom “rules” or SEO changes using the RankSense app, I recommend that you read this article first.
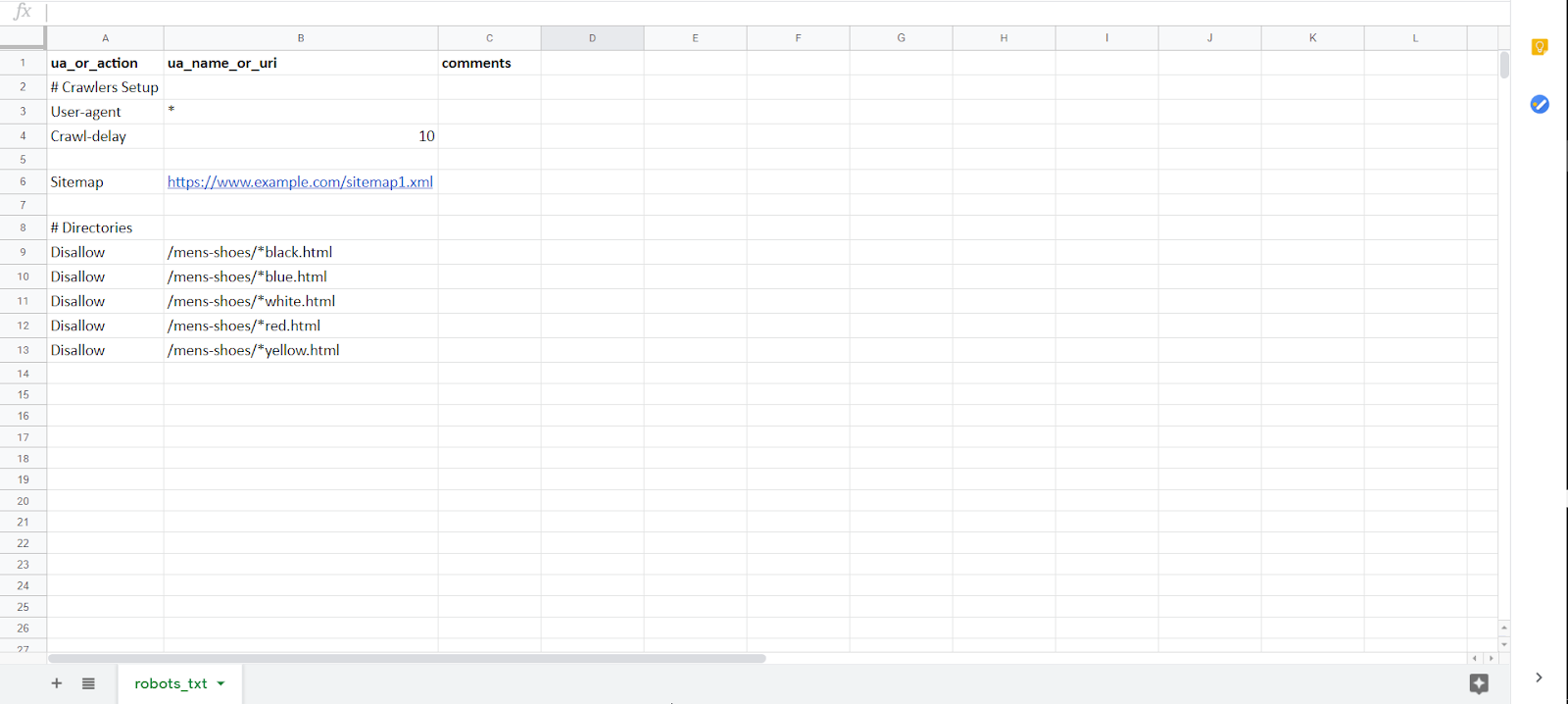
Step 2: Filling out your rule sheet
First, you will have to open the “Robots_Txt Tags” rule sheet. On this rule sheet you will see a column for the user agent or action and a column for the URL path. If you would just like to implement these rules for Googlebot, you can simply type “Googlebot” next to “User-agent.” If you would like these rules to apply to all user agents, you can type “*.”
Since we would like to add “disallow” directives, we can simply type “Disallow” under “#Directories” for a specific URL path. Considering it would be very tedious to add a disallow directive for every single duplicate URL, we can use the asterisk symbol (*) to block all URLs that start and end in a particular fashion.
For example, suppose you are implementing these rules for a website that sells men’s and women’s shoes. On the website, you can filter the product page by color, creating URLs with low quality duplicate content. By using the asterisk, you can set disallows on every URL created when the user filters for color, no matter how many other filters are selected before it.
Here is an example:
A disallow for /mens-shoes/*black can disallow a URL such as https://www.example.com/mens-shoes/sneakers/jordan-5-150-high-top-black.html. Note how many filters are selected (Jordan, size 5, price 150 and up, hightop). Instead of disallowing every combination of filters, you can disallow all combinations which end in black. By doing this for the other types of filters, you will be able to disallow a majority, if not all, of the URLs that create crawler traps.
(Note that if your site uses parameters for faceted navigation, you just need to block each URL parameter by “disallowing” the pattern the parameter uses.)
Once the rule sheet is complete, go to the RankSense dashboard and simply navigate to “Settings>SEO rules” and click the “+ File” button to add your rule sheet. Paste the URL of your spreadsheet and add the appropriate tags. Some good tags to use for this rule sheet are “Exact Duplicate Content” for the issue tag, “Add Robots.txt Directives” for the solution tag, and “Category Pages” for the affected tag.
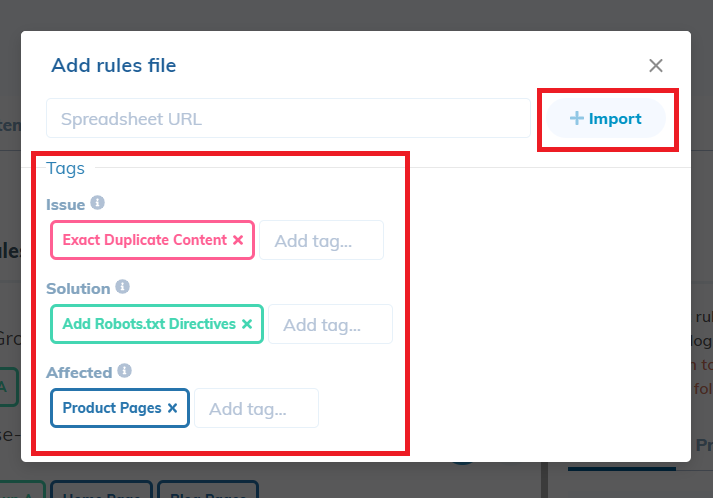
We recommended users to publish to staging first to make sure that the changes are working as intended.
(Amendment: It is extremely important to check Google Analytics to verify that these faceted URLs are not generating any organic traffic. If they are generating organic traffic and we block the URLs from being crawled, this traffic will be lost. Any faceted URLs which are generating traffic should be whitelisted in the robots.txt file above the Disallow directives. In order to whitelist a URL you must add an Allow directive followed by the URL. For example: Allow: https://www.example.com/shoes.?color=blue. These Allow directives will ensure that Google will continue to crawl the specific URLs generating traffic, while blocking the rest.
Special thanks to Pedro Dias for bringing it to our attention that we forgot to mention that we must first check whether a faceted URL is generating organic traffic before blocking it from being crawled. Read our conversation regarding the article here: Twitter thread)
Step 3: Verifying your changes
You can easily verify whether the disallow directives were successfully implemented by entering your domain name/robots.txt in the search bar (example.com/robots.txt)
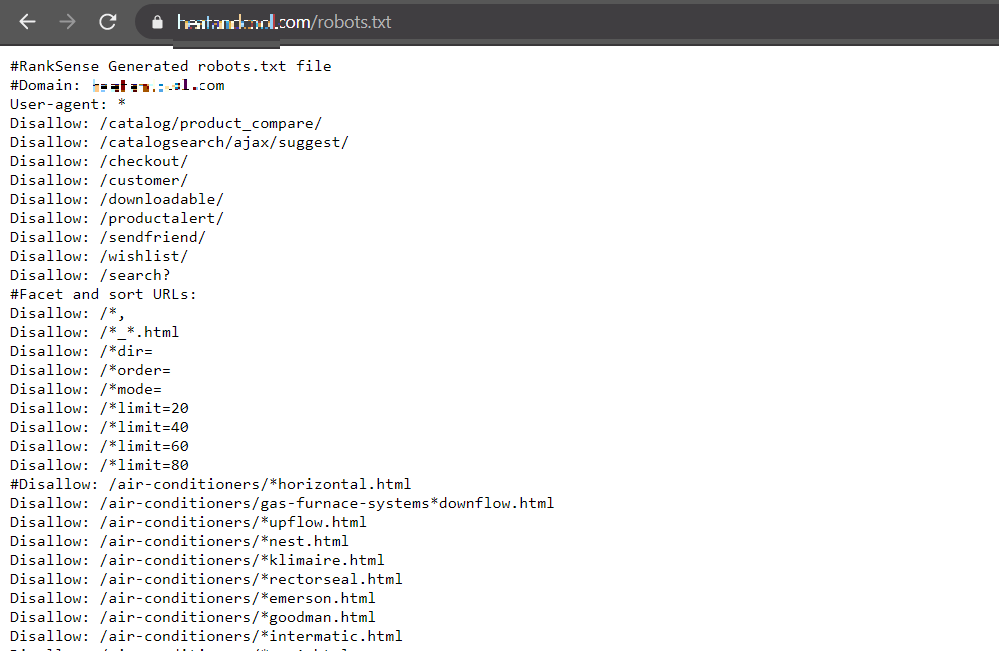
You can implement changes like this and many others on the RankSense app by using the various rule sheets.
Using the RankSense SEO tool to verify your changes
Once the RankSense Cloudflare app is set up, if you navigate to the “Pages” tab you will be able to view the exact URLs that Googlebot has crawled on your website. This tab is especially useful since you can find any URLs that you do not want to be crawled, eliminating all guesswork.
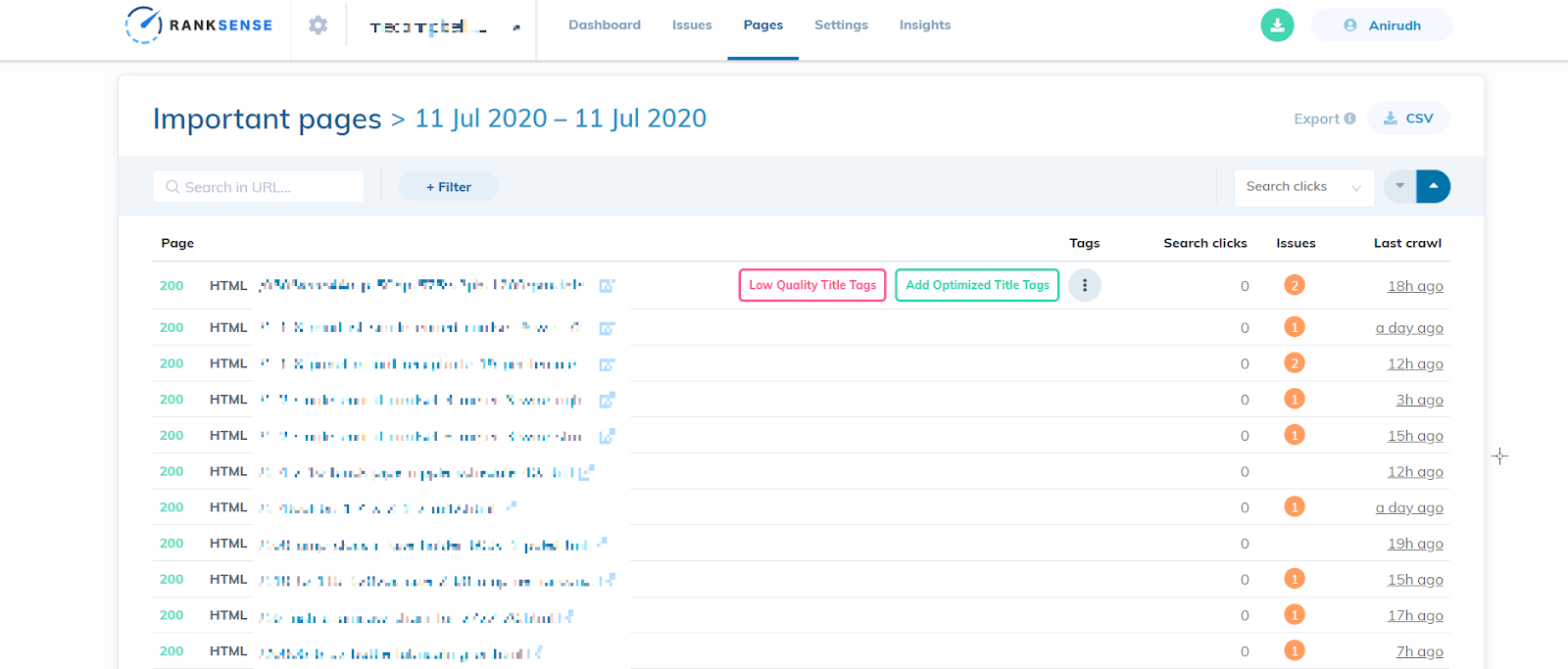
If you find any URL which could potentially cause a crawler trap, simply implement a robots.txt disallow directive on that URL pattern.
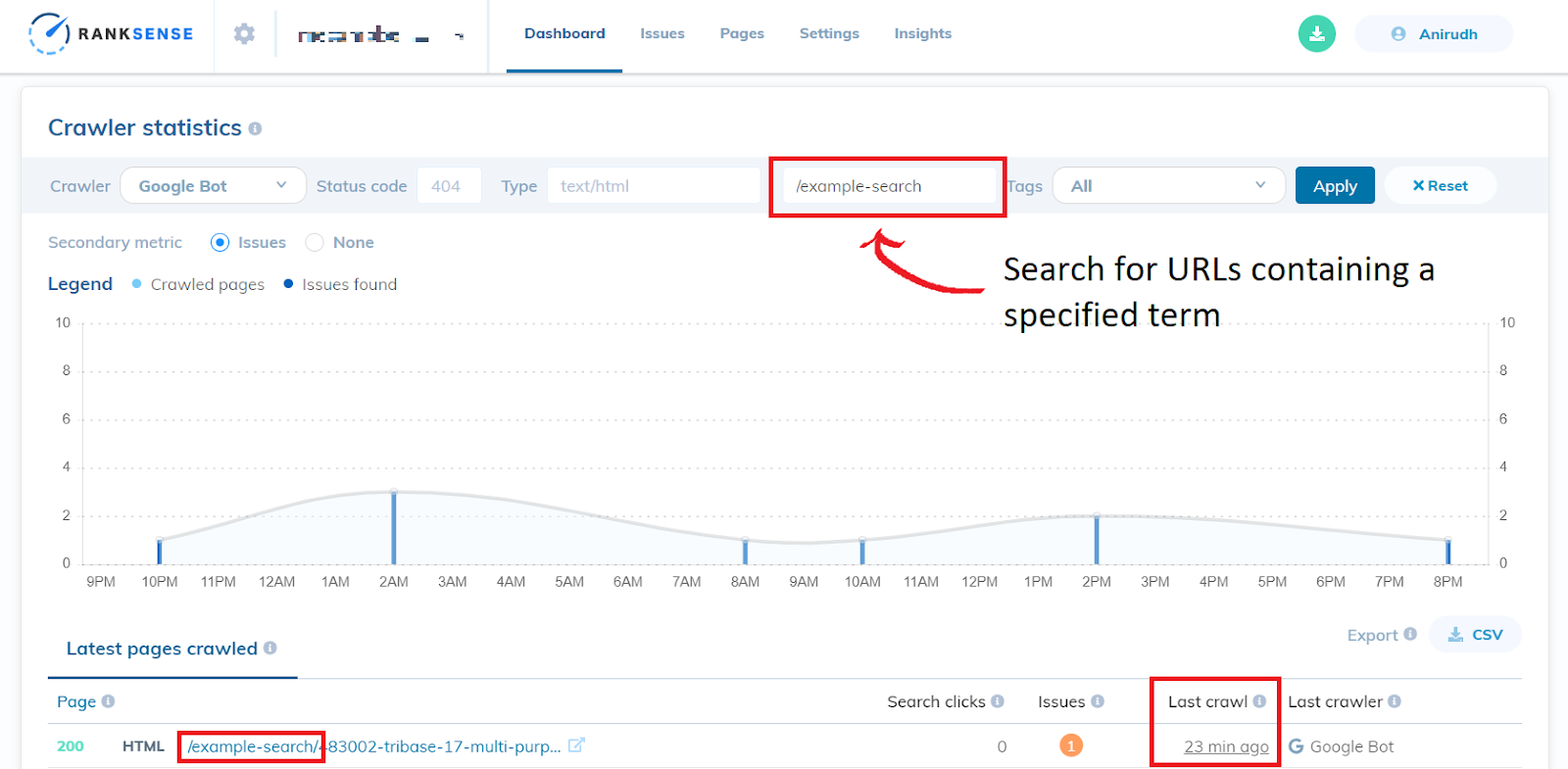
You can even search for specific URLs by scrolling down on the “Dashboard” tab to “Crawler Statistics.” Here you can search for all URLs crawled by Googlebot containing some specified text in the textbox that reads “Search in URL.” Make sure that the “Last crawl” is displaying a date before you implemented the disallow directive on that URL pattern in order to verify that Google has not crawled these types of URLs recently.
Soon we will be able to use the “Insights” tab on the RankSense app to view the effectiveness of the robots.txt directives. Nevertheless, we have seen a significant increase in organic traffic for many clients in the past after implementing these types of robots.txt directives, showing us that this method works effectively.
We learned that:
- The use of faceted navigation on a website can create crawler traps because of the thousands of URLs created that contain duplicate and low quality content.
- Robots.txt files with disallow directives for URL paths causing the crawler traps can keep crawlers from crawling duplicate content and wasting their crawl budget.
- You can identify crawler traps by either studying the website manually, using a web crawler application, or by using the “Pages” tab on the RankSense app.
- It is easy to implement the robots.txt directives using the RankSense app and check whether or not they are working as intended.
(Final Note: It is important to remember that though we have seen amazing SEO results when implementing this type of fix on large E-Commerce sites, this is essentially a “band-aid” solution. The best solution would be to implement faceted navigation in a way that does not update the URL at all. However, this type of solution can be time consuming for your developers and this can be a great way to address the problem while the proper solution is implemented. Special thanks to Tyler Reardon for mentioning this.)
